Intel CPU 微架构的演进
80486,1989 年 推出
所有486和586的祖宗。
与其前身一样,80486与所有以前的x86处理器(80386、80286、80186等)保持了完全向后 的目标代码可比性。为了提高性能,英特尔引入了新的片上缓存层(之前存在各种外部扩展)。 8 KB、4 路组关联、回写策略高速缓存对于数据和指令都是一致的。这提供了对最近使用的数据和指令的更快访问。总线接口还进行了各种增强,包括需要单个时钟周期而不是多个时钟周期的更快通信。
而在使用单独封装的数学协处理器(即80387、80287等)之前,80486 将单元移至芯片上,完全消除了外部通信延迟。此外,更先进的数学算法被用来实现新的FPU,从而产生更快的浮点计算。
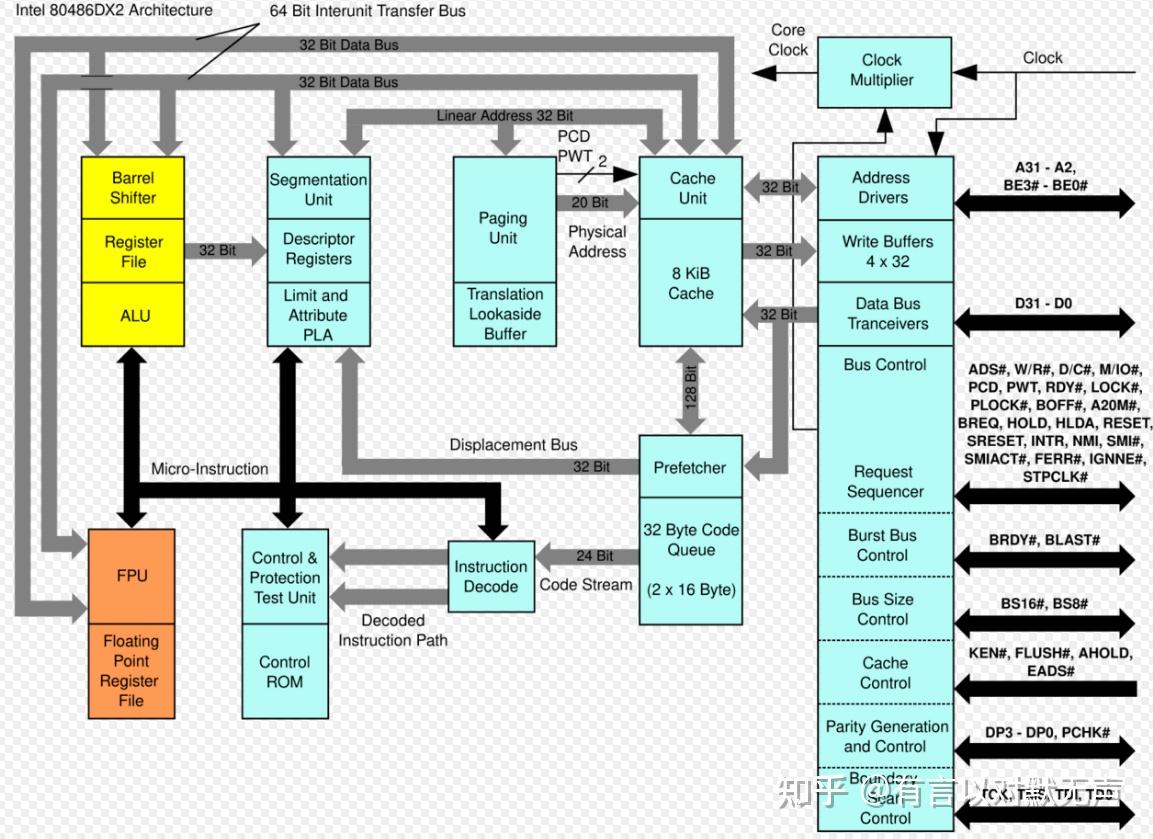
80486是Intel80486系列微处理器的微架构,是80386的后继产品。 89 年 4 月推出的 80486 最初采用1 µm 工艺(后来为800 nm)制造。对于 AMD,这种微架构用于其Am486和Am5x86系列。该架构于 1993 年被 Intel 的P5和1994 年的K5取代。

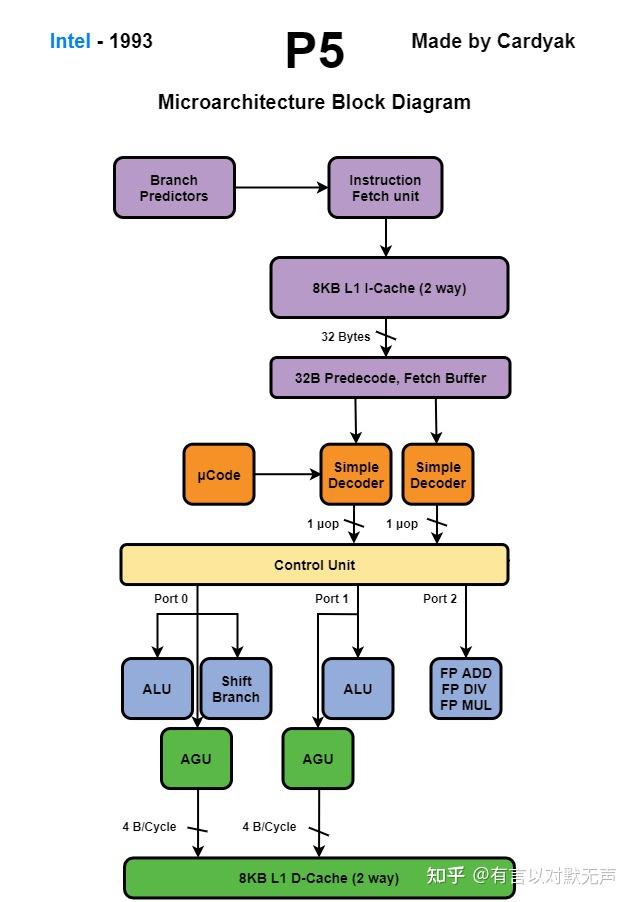
P5,1993年推出
P5 Pentium 是超标量处理器,可以同时执行两条指令,但不能乱序处理。
- P5 中的分支预测机制与其他处理器不同,因此遵循一些文档建议可能导致代码效率低下。
- P5 的分支目标缓冲区 (BTB) 最多可保存 256 个跳转指令信息,组织为 4 路组关联高速缓存。
- BTB 使用伪随机替换算法,新条目不一定取代最近最少使用的条目。
- 每个条目有一个饱和计数器,状态图显示了预测器状态。
- 缺陷导致失败分支的错误预测次数是成功分支的三倍。
- BTB 机制计算指令对而不是单个指令,需要了解指令如何配对以分析存储位置。
- 控制传输指令的 BTB 条目附加到前一个指令对的地址。
- 连续跳转可能导致刷新管道和错误预测损失。
- P5 和 PMMX 上的静态预测存在失败情况,不会获得 BTB 条目。
- P5 和 P5MMX 有两条 U/V 管道用于执行指令,可同时执行两条指令提高速度。
- 前缀指令只能在 U 管道中执行,条件邻近跳转除外。
- 重新排序指令以使其配对是有利的,但有些指令不能配对或只能在特定管道中配对。如果第二条指令遭遇 AGI 停顿,那么两条指令不会同时执行。
- 完美搭配条件包括寄存器的读写情况,MMX 指令的配对规则,以及指令的长度和地址访问情况。
- 一条可配对整数指令从内存中读取数据,进行一些计算,并将结果存储在寄存器或标志中,需要 2 个时钟周期。

P6,1995 年推出
P6是P5的后继者, 最开始发布在Pentium Pro 上,广泛使用在Pentium Pro、II 和 III 中。 P6 于 1995 年推出,一直持续到 2000 年,采用350 nm和250 nm工艺制造。 P6于 2000 年底 被NetBurst淘汰。
1995 年的 Pentium Pro 是第一款具有乱序执行功能的英特尔处理器。微架构设计相当成功。这种设计经过多代的进一步发展,形成了我们今天拥有的处理器——稍微绕道了不太成功的 Pentium 4 或 Netburst 架构。
P6大概有14~15个分支预测错误惩罚周期,经常受到寄存器读取停顿影响。所有基于 P6 微架构及其后继产品、Pentium M、Core 和 Nehalem 微架构的 Intel 处理器都有每个时钟周期从寄存器文件读取两到三次的限制。
- 指令长度解码:
- P6 微架构的指令长度解码器能确定每个时钟周期的三个指令长度,并反馈给指令获取单元以生成新的 IFETCH 块。
- 它支持并行解码所有 16 个可能的起始地址。
- 指令解码器和解码组:
- 指令解码器将指令转换为微指令,三个解码器 D0、D1 和 D2 并行工作,每个时钟周期最多解码三个指令。
- D0 每个周期最多生成 4 µops,D1 和 D2 只处理简单指令,每条指令最多生成 1 µop,长度不超过 8 字节。
- IFETCH 块中第一条指令总是指向 D0,接下来的两条可能指向 D1 和 D2。
- 如果某指令无法由 D1 或 D2 处理,则需等 D0 为空,后续指令也会延迟。
- 寄存器读停顿:
- 通过性能监视器编号 0A2H 可检测寄存器读停顿,无法区分其他类型的资源停顿。
- 避免停顿的方法包括按规则排序指令、延迟读取寄存器等策略。
- 乱序执行和退出:
- 重排序缓冲区可容纳 40 µops 和 40 个临时寄存器,退休站每个时钟周期处理三个微指令。
- 指令乱序执行、内存写入不能乱序执行。
- 避免内存写入读取可能的误执行需要确保执行单元有其他任务可执行。
- 预测执行下的 µop 在预测正确前无法退出。
- 部分标志停顿后读取:
- 部分标志停顿在读取标志位的指令上发生,例如 LAHF、PUSHF、INC、DEC 等。
- 移位或旋转后读取标志位可能引起停顿,但某些情况下不会发生。
- 存储转发停顿:
- 存储转发停顿类似于部分寄存器停顿,发生在混合数据大小的同一内存地址上


NetBurst,2000年推出
NetBurst(也称为P68)是P6的后继者,它是大名鼎鼎的Pentium 4的微架构,桌面端64位单核x86微处理器。 NetBurst于 2006 年初 被Core微架构取代。
- Willamette 核心
- 180 nm
- Northwood 核心
- 130 nm
- Prescott 核心
- 90 nm
- Cedar Mill 核心
- 65nm
从2000年~2006年,打磨了整整4代。
- Netburst 架构是当时庞大的核心。与其前身 Pentium III 相比,Pentium 4 拥有更多执行资源和更大的乱序结构。与竞争对手 AMD 的 Athlon 64 以及它的后继者 Merom 相比,它也是一个大型核心。
- 与基于英特尔 P6 架构的 Pentium III 相比,Netburst 处于完全不同的规模上。虽然两者都有三倍宽的流水线,但 Netburst 上的每个关键乱序结构都大得多。
- 分支预测对于任何 CPU 都非常重要,尤其适用于高频长流水线的 Netburst 。它需要非常好的分支预测准确性来利用其庞大(当时而言)的重排序能力。
- Netburst 使用了一个具有 16 位全局历史缓冲区的两级自适应预测器,其分支预测能力在当时非常先进。Netburst 可以跟踪超过 1024 个分支并处理它们。 N - etburst 的零气泡BTB被塞满后,分支处理速度急剧下降。可能使用了其 4096 条目 BTB,并且该处理路径非常缓慢。
- Merom 和 Westmere 是 Netburst 的后继者,它们无法在小分支占用空间时达到相同的速度。
- Netburst 的指令缓存策略有其优势,跳过指令解码具有明显的延迟、带宽和功耗优势。
- Netburst 的重命名和分配阶段是 3 宽的。它能够识别零化惯用语和消除假依赖关系。
- Netburst 的乱序结构非常庞大,在 Nehalem 推出之前无法匹配。但是,这种架构导致了一些问题,例如处理缓存丢失和取消伪指令的能力。
- Netburst 的存储转发和加载/存储单元机制相对原始。存储转发仅对地址完全匹配的情况成功。
- Netburst 的 L1 数据缓存和 L2 缓存带宽相对较低,尤其是对于更大的工作集。与 AMD 相比,Netburst 的 L1D 读取带宽较低,但是其高时钟频率弥补了一部分延迟。
- Netburst 对于非对齐的内存访问成本较高,导致性能下降。写入带宽较低是因为它使用了写入直通 L1D 缓存。
- Intel 在 Netburst 中引入了大量新的微架构技术,但风险较高,最终未能实现预期的性能和IPC提升。


Pentium M,2003 年推出
Pentium M是改进的Intel P6 微体系结构
- Pentium M是一种移动端32位单核x86微处理器系列,于2003年3月推出。
- 与面向桌面的Pentium 4低功耗版本不同,它是Pentium III Tualatin设计的大幅修改版本。
- 优化了电源效率,延长了笔记本电脑电池寿命,平均功耗低且发热量也低。
- 时钟速度低于Pentium 4,但性能相似,主要针对电池寿命和功耗进行优化。
- PM与P6流水线几乎相同,但更长,并且分支预测机制更复杂,可能需要三级。
- 指令获取改进,不受边界或高速缓存行边界影响,新的堆栈引擎在指令解码附近实现。
- µop融合机制未必需要额外阶段,ROB读取到写回仅有3个时钟。
- PM流水线可能比P6多3或4级,包括用于分支预测、指令获取和堆栈引擎的额外级。
- µop融合、堆栈引擎和复杂的分支预测都是改进,降低功耗,加快执行速度。
- 支持SSE2,拥有专用寄存器堆栈管理。
- 简化分支预测表,添加全局历史、间接预测和循环预测。
- PM中指令取得方式与PPro、P2和P3相同,但预测跳转的效率更高。
- 解码工作方式相同,PM有三个并行解码器:D0、D1和D2。
- 未融合的微指令从保留站提交到连接到所有执行单元的五个执行端口。
- PM有4x16字节循环缓冲区存储预解码指令,在取指令成为瓶颈的小循环中有优势。
- 存储器写操作在PM上融合,但读取-修改操作需两微指令。
- PM的ROB重新设计,每条目最多3输入相关性,µop融合有多个优点。
- PM的最大输出为每周期6微指令,避免指令派遣单元需根据4-1-1模式调度指令。
- 执行单元的最大吞吐量为每个时钟周期5个未融合微操作,每个端口一个。
- 端口0和1都有一个整数ALU,可以同时处理最常见的整数指令。
- PM可以同时进行浮点加法和整数加法,但不能同时进行浮点乘法和整数乘法。
- 整数加法等简单指令具有一个时钟周期的延迟,乘法单元采用流水线方式。
- 128位XMM操作被分成两个64位µop,除非输出仅为64位。
- PM的执行单元均匀分布在端口0和1之间,许多指令可以发送到这两个端口中的任何一个。
- 毫无疑问,PM的实现机制旨在提高性能,但存在一些弊端,如代码执行时间较长等。

Yonah ,2006 年推出
Yonah是改进型 Pentium M ,该微架构介于 先前的Pentium M 和后续 Core 微架构之间
- 65nm
- 支持SSE3
- 单核和双核技术,具有 2 MB 共享二级缓存
- 提高 FSB 速度,FSB 运行速度为 533 MT/s 或 667 MT/s
- 12 级流水线
Yonah 和 Core2 中的分支预测机制是相同的,误预测损失约为 12~13 个时钟周期.
Yonah有更多机会进行 XMM 指令的 µop 融合。 128 位 XMM 指令由 64 位执行单元中的两个或多个 64 位微指令处理
Yonah和 Pentium M 中的误预测损失约为 13 个时钟周期,Core2 中的误预测损失约为 15 个时钟周期,与流水线的长度相对应。无法预测远跳、远调用和远返回。

Core ,2006 年推出
Intel Core微架构,首代核心为65nm的Merom)是Intel于2006年中期推出的多核处理器微架构。它是对Yonah 的一次重大演变,Yonah 是P6 微架构系列的上一代迭代,该系列始于 1995 年的Pentium Pro。它支持X86-64,取代了NetBurst微架构,后者由于为高时钟速率设计的超长流水线而遭受高频低能的嘲笑。
第二代核心为Penryn,45 nm 缩小的 Core 微架构,具有更大的缓存、更高的FSB和时钟速度、支持SSE4.1指令、支持 XOP 和 F/SAVE 和 F/STORE 指令、增强的寄存器别名表和更大的整数寄存器文件。
Core微架构是一个重大的架构升级,它部分基于Intel 以色列团队设计的Pentium M处理器系列。Core 中的误预测损失约为 14~15 个时钟周期,不到Prescott的一半。 Penryn 的后继者Nehalem的分支误预测惩罚比 Core/Penryn 高两个周期。分支预测机制比以前的处理器更先进。条件跳转由结合两级预测器和循环计数器的混合预测器处理。此外,还有一种预测间接跳转和间接调用的机制
与P6、Pentium M和NetBurst微架构的 3 个 IPC 功能相比,在理想情况下可以维持最多 4 个指令/周期(IPC) 执行速率。
新架构采用双核设计,具有共享二级缓存,旨在实现最高每瓦性能和改进的可扩展性。
该设计中包含的一项新技术是Macro-Ops Fusion,它将两条x86指令融合成一个微指令。例如,像比较和条件跳转这样的通用代码序列将成为单个微操作。然而,该技术不适用于 64 位模式。
它可以推测性地在具有未知地址的先前存储之前执行加载。
其他新技术包括所有 128 位 SSE 指令的 1 个周期吞吐量(之前为 2 个周期)和新的节能设计。
- Penryn是Merom的45纳米缩小版,代表了Intel P6架构的巨大进化。相较于P6系列中的Core Solo和Pentium M前辈,Penryn更宽更深更先进。Merom还为P6增加了64位执行,而Penryn继续沿用。尽管有这些巨大进步,Penryn仍保留了一些明显的P6特征,比如大型的联合式调度器和ROB+RRF的乱序执行方案。
- 在许多方面,Penryn看起来比Netburst更小、不那么复杂。但与Netburst不同,Merom和Penryn在通用指令上执行得非常出色。它们拥有大型、低延迟的缓存。各种复杂情况下的惩罚大多是合理的,不像Netburst那样。
- Netburst的错误预测惩罚甚至比Intel发布的流水线长度暗示的还要高,因为在错误预测分支后无法取消错误获取的指令,只能强制执行。分支预测器不仅需要准确,还需要快速。为了快速提供分支目标,Penryn拥有2048个条目的BTB。
- Penryn还可以处理多达四个被采用的分支而没有流水线气泡。从某种意义上说,这与Netburst相比是一个退步,因为Netburst可以处理超过1024个分支且延迟只有1个周期。然而,Penryn在一级BTB失效后表现更好。2048个条目的BTB只有一个惩罚周期。
- Penryn因此对于2000年代后期的高性能CPU来说有一个不错的分支预测器。预测准确性比现代桌面CPU要差。但即使是一个一般的分支预测器也能有很大作用,而Penryn的分支预测器仍然足够准确地预测绝大多数的分支。
- 前端:指令获取与之前的P6 CPU一样,Penryn使用传统的32 KB L1指令缓存。与Pentium M相比,解码器现在是4个宽度而不是3个宽度。有趣的是,Intel最初希望将P6扩展为4个宽度,但意识到以更高时钟速度的3个宽度核心可以获得更好的整体性能。
- 与Netburst的跟踪缓存相比,Penryn的L1指令缓存更容易受到指令获取带宽瓶颈的影响。但只要指令长度保持相对较短,Penryn应该会看到更高的前端带宽。传统的指令缓存还可以更好地利用x86的指令密度,并有效地利用缓存容量。
- 尽管Penryn有一个宽的传统解码器,但核心在从L2运行代码方面仍然相当慢。在L1i失效后,核心无法超过1个IPC,即使是4字节的指令也是如此。K10的行为类似,尽管AMD受益于更大的指令缓存,因此不太可能遭受L2代码获取的惩罚。随着代码占用越来越大,这两种架构交换性能排位。
- 如果代码完全溢出缓存,与K10相比,Dunnington会受到影响。客户端Penryn并不那么糟糕,并在从DRAM获取指令时实现与K10的粗略相等。Penryn的重命名器在识别到清零习惯用法时可以打破依赖关系,但无法完全消除它们。
- 即使一条指令保证清零一个寄存器,它仍然需要通过ALU管道。K10的重命名器类似,所以与K10一样,Penryn可能会受到这种惩罚。Penryn可以消除一些习惯用法,并通过实现大型ROB和统一调度器来提高效率。
- 分支整流器不仅需要准确,还需要快速。Penryn使用统一的分支整流器,能够在单个周期处理多达四个分支。这对于分支密集型代码非常重要。K10使用统一的分支整流器,能够处理多达两个分支。Penryn因此对分支语句造成瓶颈主导的代码更有效。
- Penryn的ROB可以保存128个微操作。这意味着即使有大量的分支代码,Penryn也可以保持高IPC。这对于类似Netburst的长乱序流水线至关重要。
- Penryn的L3缓存延迟约为37 ns,比AMD的L3缓存延迟高得多。
- L3带宽也不足。使用8 MB的测试大小,单个核心只能从L3获取8.2 GB/s。在簇中使用两个核心,得到9.49 GB/s。如果我们开始加载套接字中的所有核心,L3基本上就消失了。这是因为L3包含了上一级缓存的内容。如果Penryn的三个簇分别缓存不同的数据,则只有3 MB的L3容量是有用的。
- 对于IO连接,MCH具有28条PCIe 1.0通道,另外有四条专用通道连接到南桥。
- Penryn展示了对于高性能CPU来说,低延迟和低惩罚的缓存层次结构比花哨的架构特性更为重要。当然,先进的分支预测器和依赖预测器有所帮助。大型乱序执行缓冲区也有所帮助。但它们不能作为解决严重架构缺陷的良好应对机制,就像我们在Netburst中看到的那样。Merom因此成为Intel高端产品的一种架构重置。随着Nehalem和Sandy Bridge的推出,Intel逐渐将Netburst的先进特性与P6系列相结合,打造出了AMD数年内无法匹敌的产品。
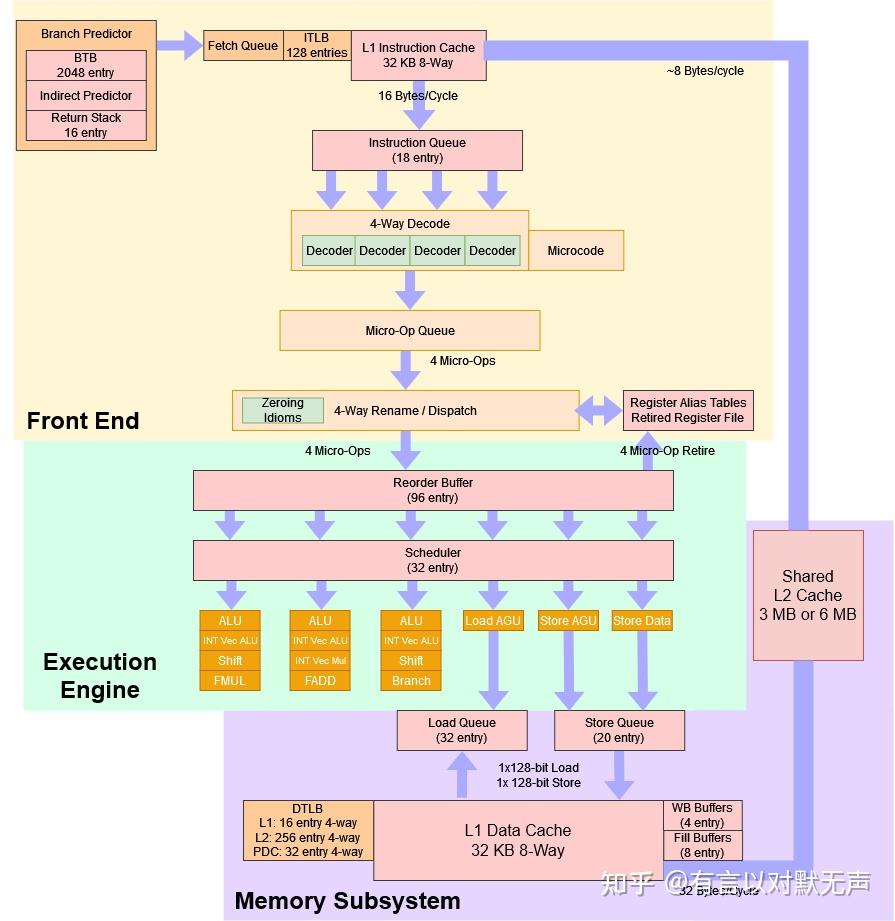
Nehalem,2008 年推出
首代酷睿系列的微架构
Westmere: 32 nm的Nehalem 微架构,具有多项新功能
- L2/L3 高速缓存上的高速缓存行块从 NetBurst & Merom/Penryn 中的 128 字节减少到这一代中每行 64 字节(与 Yonah 和 Pentium M 大小相同)。
- 重新引入超线程。
- 英特尔睿频加速1.0。
- 某些型号具有智能缓存的2–24 MiB L3 缓存。
- 指令获取单元(IFU) 包含二级分支预测器,具有二级分支目标缓冲区(BTB) 和返回堆栈缓冲区(RSB)。 Nehalem 还支持英特尔处理器之前使用的所有预测器类型,例如间接预测器和循环检测器
- sTLB(二级统一转换后备缓冲区)(即指令和数据)仅包含小页面的 512 个条目,并且再次是 4 路关联。
- 每个核心 3 个整数 ALU、2 个矢量 ALU 和 2 个 AGU
- 本机(单个芯片上的所有处理器内核)四核、六核和八核处理器
- 每个内核 64 KB L1 缓存(32 KB L1 数据和 32 KB L1 指令),每个内核 256 KB L2 缓存。
- 将PCI Express和DMI集成到中端型号的处理器中,取代北桥。
- 集成内存控制器支持两个或三个DDR3 SDRAM内存通道或四个FB-DIMM2通道。
- 第二代英特尔虚拟化技术,引入了扩展页表支持、虚拟处理器标识符 (VPID) 和不可屏蔽中断窗口退出。
- SSE4.2和POPCNT说明。
- 宏指令融合现在可以在 64 位模式下运行。
- 20 至 24 个流水线级。
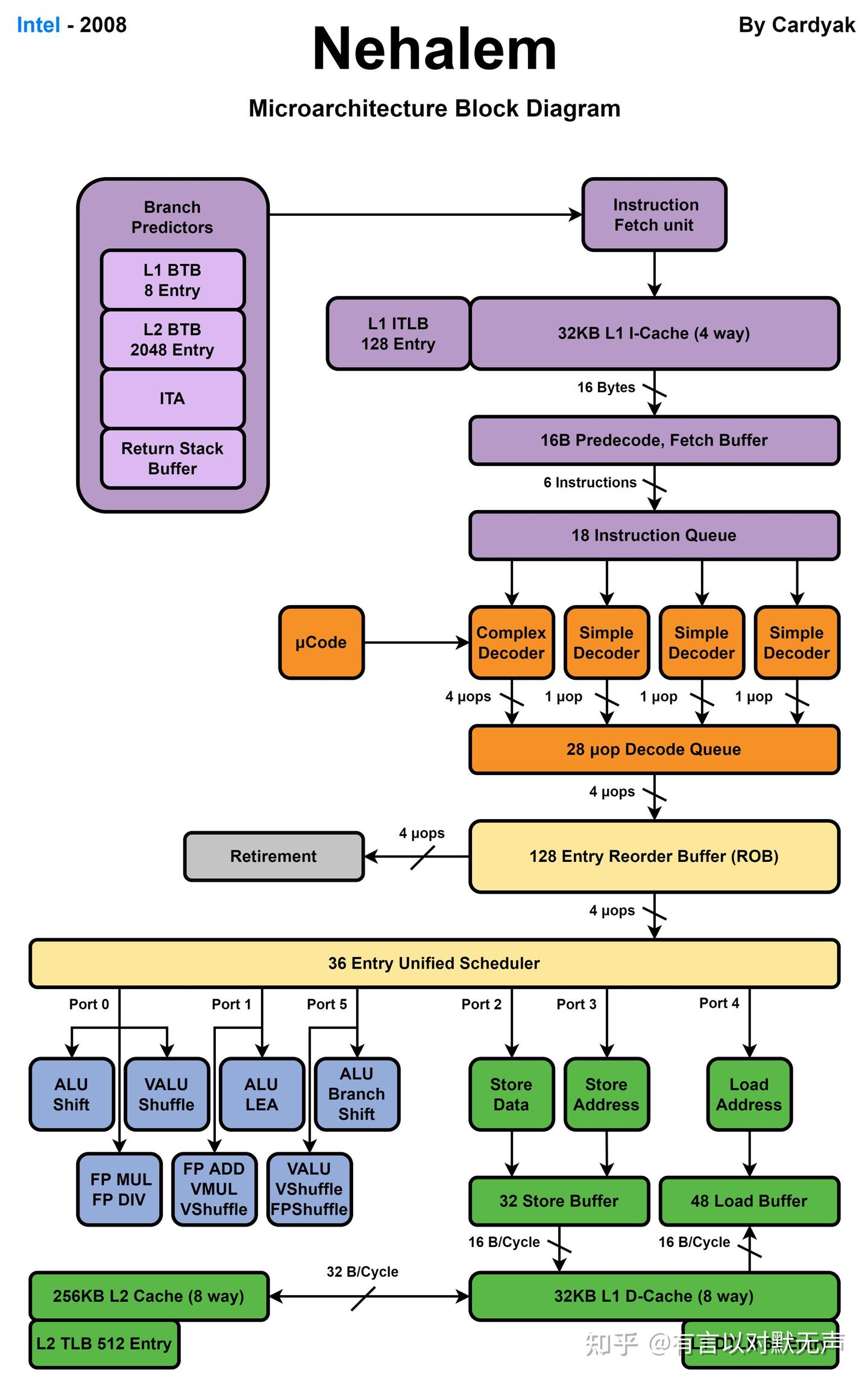

Bonnell,2008年推出
Bonnell是英特尔45 nm超低电压微处理器的微架构,于 2008 年首次为其当时的新Atom系列推出。 Bonnell以美国低功耗处理器设计团队扎堆的奥斯汀的最高点——MountBonnell命名,是英特尔首款兼容x86-64的低功耗微架构,旨在瞄准超低功耗市场,与VIA竞争。
Bonnell(当时的 Silverthorne 项目)是由英特尔于 2004 年在奥斯汀德克萨斯开发中心创建的当时新的低功耗设计团队以及新的芯片组 (Poulsbo) 设计团队设计的。设计团队由埃莉诺拉·约利 (Elinora Yoeli) 领导。 Yoeli 之前在她的祖国工作过,而 Bonnell 由美国设计,与海法以色列设计中心从事的任何英特尔项目都没有关系。此前,Yoeli 曾领导以色列团队开发PentiumM。
Bonnell 的架构与其他英特尔设计几乎没有共同之处,当然它可能参考了古老的P5微架构。为了实现严格的超低功耗目标,Bonnell 采用了非常精简的设计,放弃了英特尔高性能架构所使用的许多高性能技术,例如激进的推测执行、乱序执行和 µop 转换。
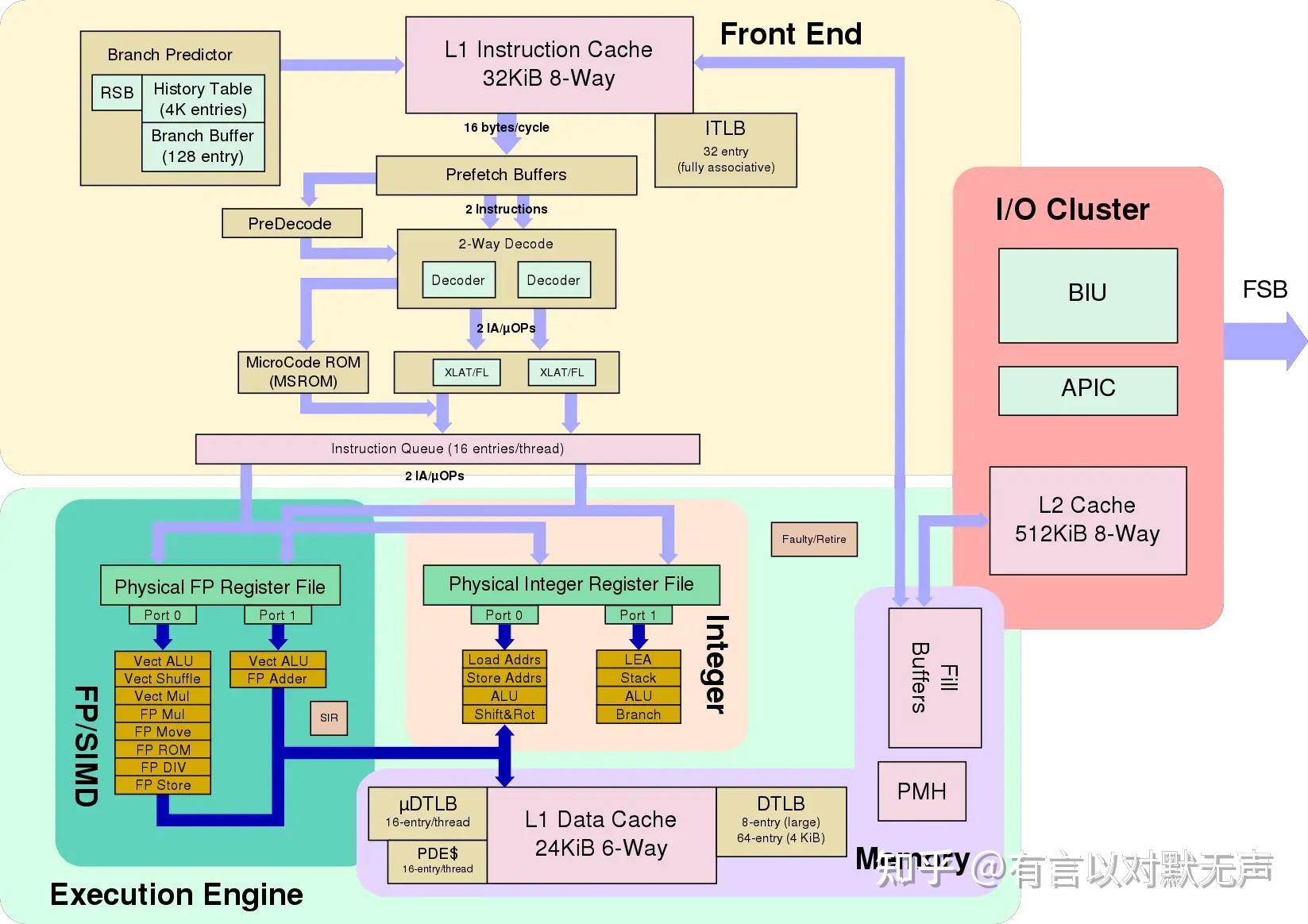

Sandy Bridge,2011年推出
使用的32 nm。 Sandy Bridge 微体系结构是Nehalem和Westmere 微体系结构的后继者。
- 英特尔睿频加速2.0
- 每个核心32KB数据+32KB指令L1缓存和256 KBL2缓存
- 共享L3缓存,其中包括处理器显卡(LGA 1155)
- 64字节缓存线大小
- 新的uOP缓存,最多1536项
- 每个核心改进了3个整数ALU、2个向量ALU和2个AGU
- 每个内存通道的每个CPU周期两次加载/存储操作
- 解码微操作缓存和放大、优化的分支预测器
- Sandy Bridge 保留了Nehalem 中的四个分支预测器:分支目标缓冲区(BTB)、间接分支目标数组、循环检测器和重命名的返回堆栈缓冲区(RSB)。Sandy Bridge有一个BTB,其分支目标数量是Nehalem中L1和L2 BTB的两倍。
- 改进了AVX、AES加密(AES指令集)和SHA-1哈希的性能
- 内核、图形、缓存和系统代理域之间的256位/周期环形总线互连
- 高级向量扩展(AVX)256位指令集,具有更宽的向量、新的可扩展语法和丰富的功能
- 多达8个物理核心,或通过超线程实现16个逻辑核心(6核心/12线程)
- 将GMCH(集成图形和内存控制器)和处理器集成到处理器封装内的单个芯片中。相比之下,Sandy Bridge 的前身Clarkdale在处理器封装内有两个独立的芯片(一个用于GMCH,一个用于处理器)。这种更紧密的集成进一步减少了内存延迟。
- 14至19级指令流水线,取决于微指令缓存命中或未命中
Saltwell, 2011 年底推出
32 nm超低功耗微架构,Saltwell 的流水线与Bonnell 的流水线几乎相同,均为 16 级流水线,并有 13 级未命中惩罚。它仍然是一个双发射超标量架构,按顺序执行。由于功率和面积限制,重新排序逻辑仍然被省略。它拥有更大的指令获取,将分支预测历史表的大小加倍。
Ivy Bridge,2011年推出
Ivy Bridge 采用22 nm。这是英特尔第一代FinFET。Ivy Bridge引入了一些新指令。
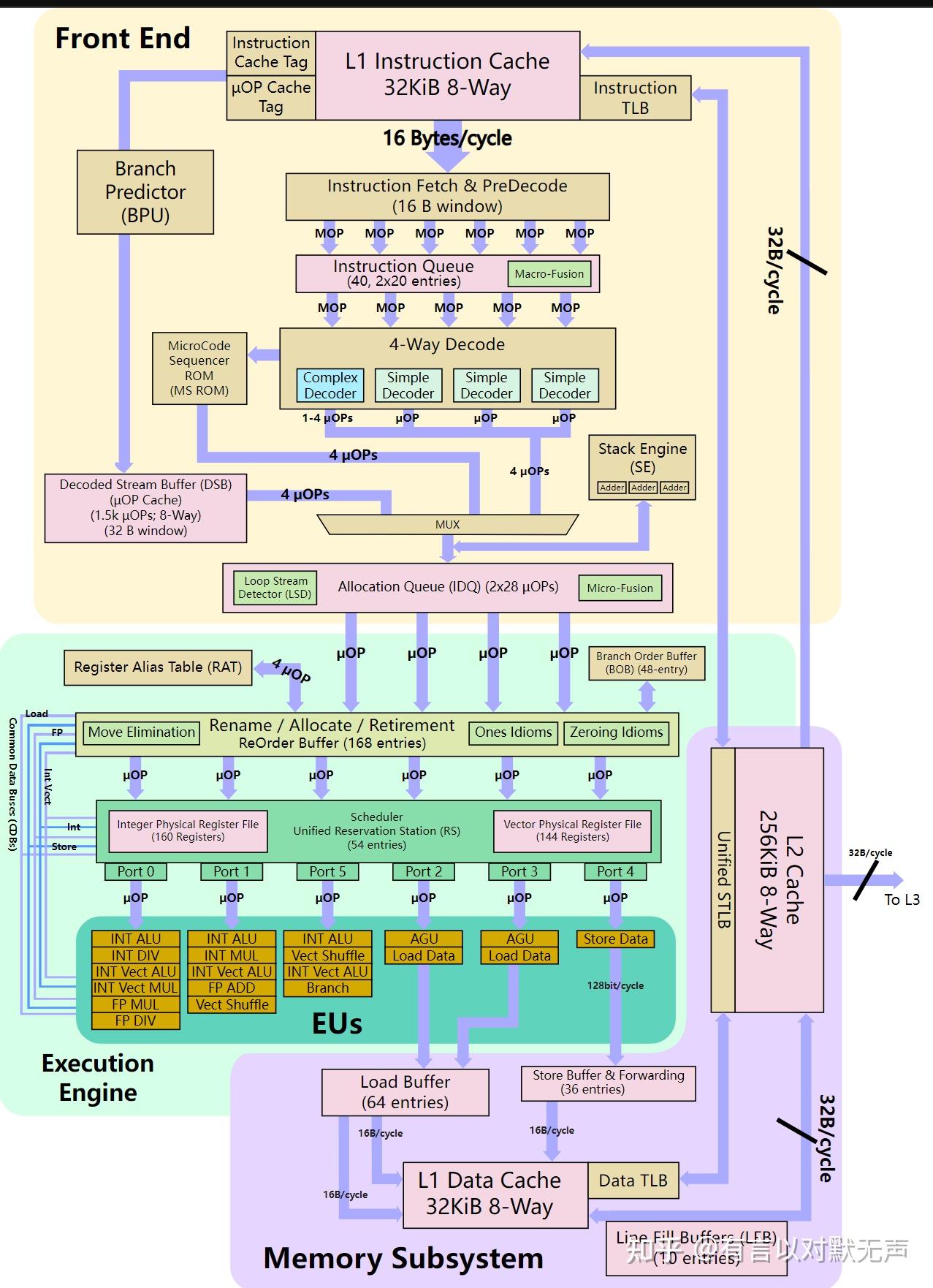
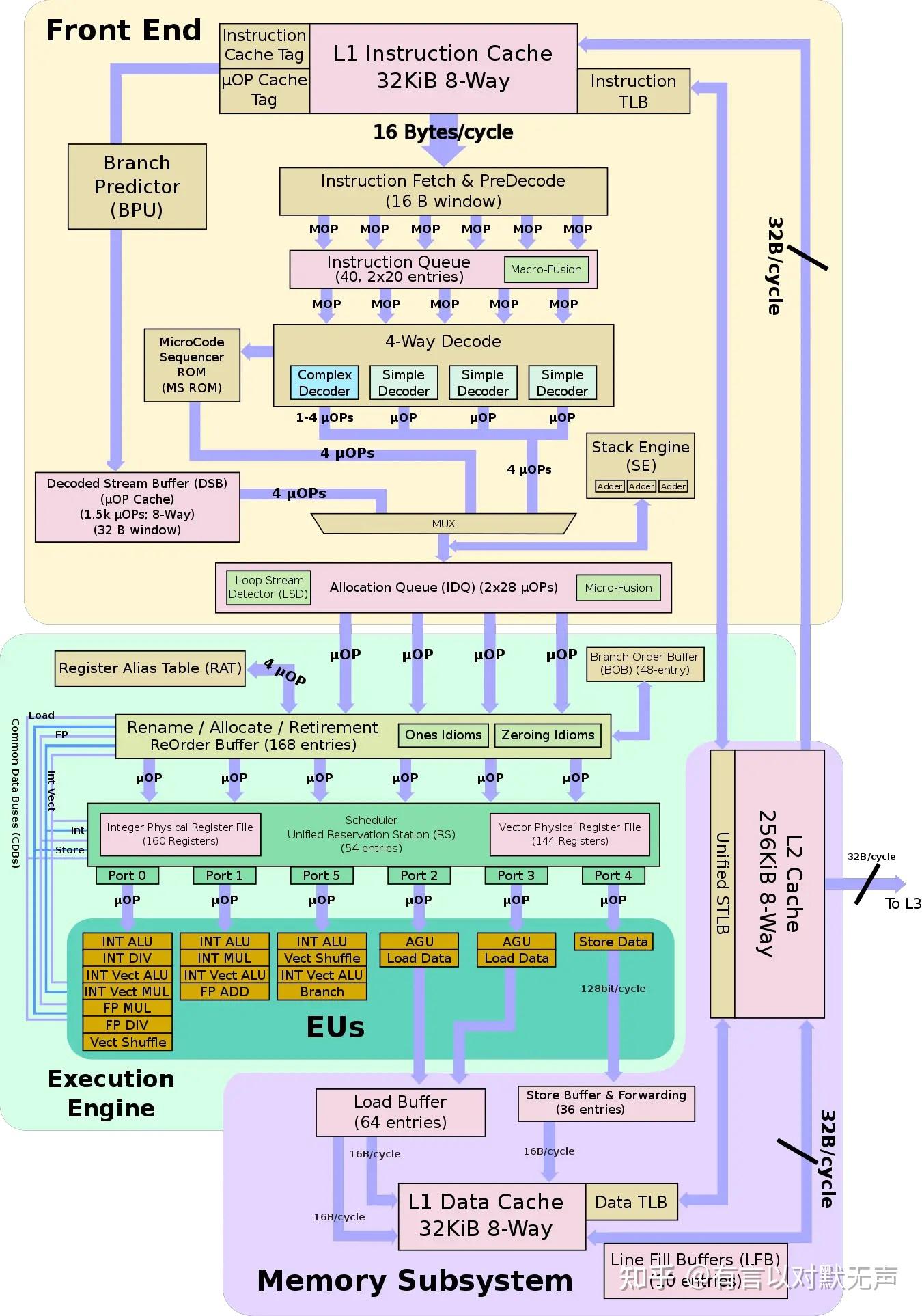
Haswell,2013年推出
Haswell于2013年推出,它采用22nm是Ivy Bridge的继任者。
- 前端处理1到15字节的可变长度x86指令,主要目标是正确获取并解码下一组指令。
- 拥有一个全新升级的分支预测器,可能是改进型TAGE分支预测器
- Haswell的L1i$仍然是32KB,8路组关联由两个线程动态共享,指令高速缓存保持为16B/周期。
- TLB仍然是128条目、4路4KB页面模式和8条目、完全关联2MB页面模式。
- 指令队列有40个条目,每个线程20个,Haswell继续改进分支失误。
- Haswell具有与Ivy Bridge相同的µOps缓存,每组可产生高达4µOps/周期。
- 高速缓存支持微编码指令,缓存由两个线程共享。
- 解码器有3个简单解码器和1个复杂解码器,总能发出3个单一融合µOps和额外的1-4个融合µOps。
- ROB已增加到192个条目,每个条目对应一个µOp,ROB固定分割在两个线程之间。
- Haswell继续对所有µOps使用统一的调度程序,其中包含60个条目,µOps可能会因资源不可用而暂停。
- Haswell通过两个端口扩展了调度器,使总数达到8µOps/周期,各个端口也进行了重新平衡。
- 新的端口6添加了另一个整数ALU设计,和第二个分支单元以降低端口0的拥塞。
- 添加的第二个端口(端口7)添加了一个新的AGU,端口0的ALU/Mul/shifter扩展到256位。
- Haswell的性能峰值可以是Sandy Bridge的两倍以上,调度器通过调度端口以FIFO顺序调度最多8个就绪µOps/周期。
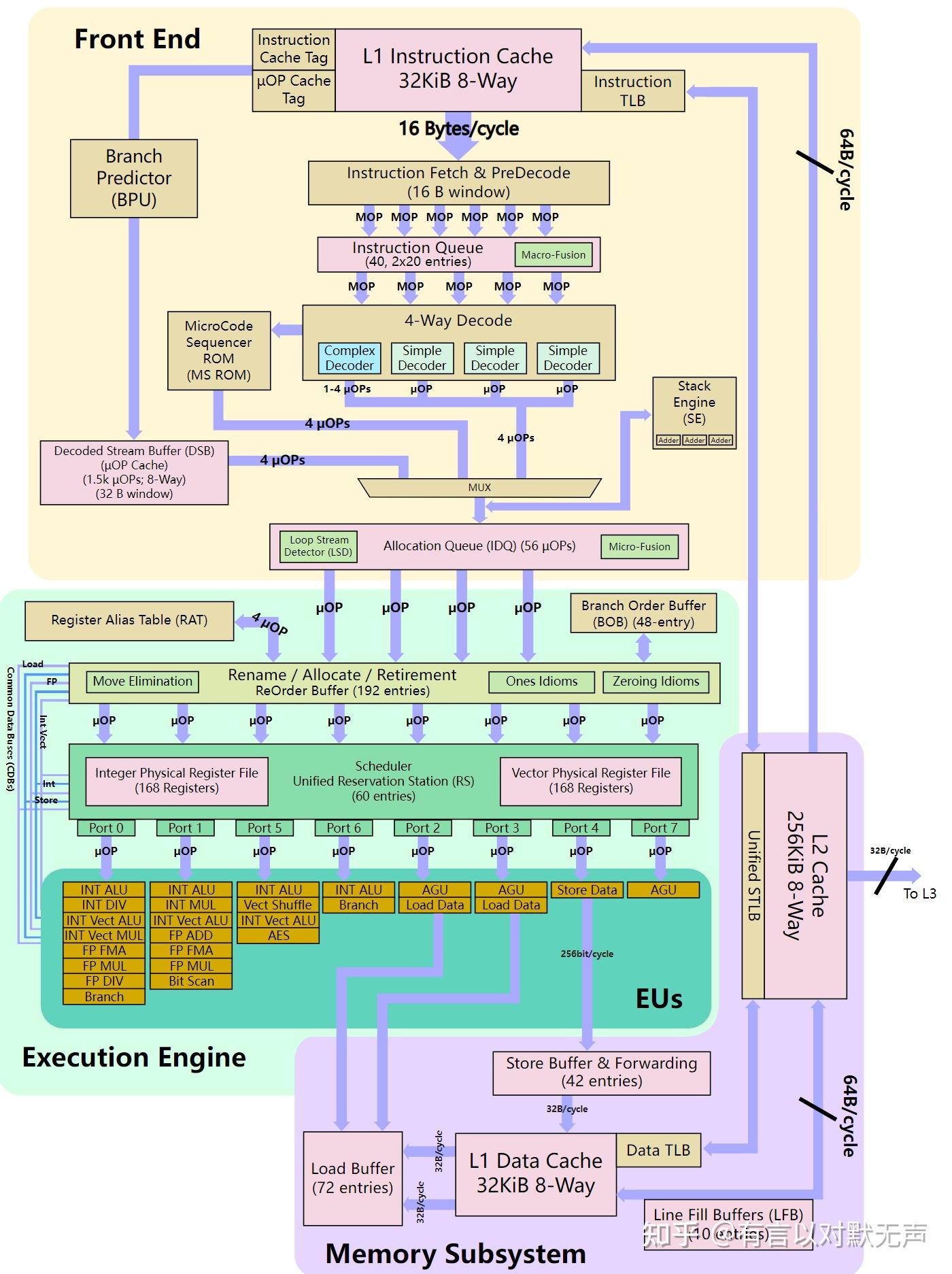

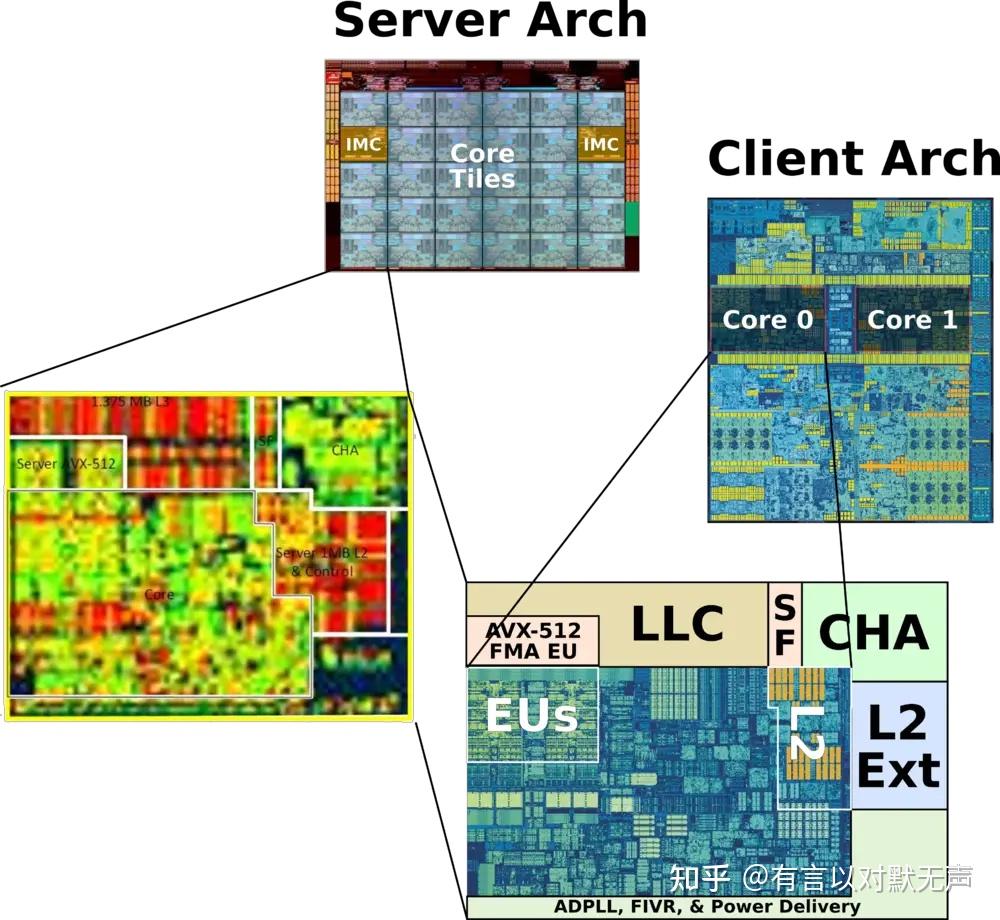
Silvermont , 2013 年推出
Silvermont(SLM) 基于22nm。 Silvermont 于 2013 年推出,是Saltwell的后继者。
- Silvermont 引入了许多重大变化。
- 与 Saltwell 一样,该流水线仍然采用双发射设计;但它的流水线缩短了 2 级,分支误预测损失降低了 3 个周期。
- Silvermont 是第一个引入乱序执行(OoOE) 的微架构。
- Silvermont 流水线解码并发出 2 条指令并调度 5 个操作/周期。
- 指令获取,就像之前的微架构一样,构成了流水线的前三个阶段。然而,随着乱序执行的引入,Silvermont 更积极的获取和分支预测意味着停滞的指令不会像 Saltwell 那样阻塞整个流水线。
- 在前几代微架构中,通用软件代码中大约有 5% 的指令被分成微操作。在 Silvermont,这一比例降至仅 1-2%。这种减少会直接转化为性能,因为它消除了 3-4 个额外周期的开销。
- Silvermont 有第二个分支预测器,可以根据先前未知的信息(例如来自内存或寄存器的目标地址)做出更准确的预测,并覆盖通用预测器。尽管如此,分支误预测惩罚的代价也减少了 3 个阶段(从 Saltwell 的 13 个周期减少到 10 个周期)。
- Silvermont 有两个分支预测:一个控制指令提取,第二个可以在收集附加信息后在解码阶段覆盖第一个分支预测。第二个预测器控制推测指令的发出。对于第一个预测器,Silvermont 使用分支目标缓冲区来确定下一个获取地址,其中还包括用于调用和返回处理的 4 条目返回堆栈缓冲区。
Broadwell ,2015 年推出
Broadwell(BDW) 。 Broadwell 于 2015 年初推出,是Haswell的14nm工艺缩小版。
- FP 乘法指令减少了延迟(从 5 个周期减少到 3 个周期)
- 影响 AVX、SSE 和 FP 指令
- CLMUL指令现在是单个µOP,改善了延迟和吞吐量
- 二级TLB(STLB)
- TLB表已扩大(从 1024 个增加到1,536 个条目)
- 1GB页面模式(16个条目,4路组关联)
- 更大的调度程序(从 60 个增加到,64 个条目)
- 更大的指令队列(每线程从 20 个增加到, 25 个条目)
- 更快的存储到加载转发
- 改进了分支和返回的地址预测
- 改进的密码学加速指令


Airmont , 2015 年推出
Airmont基于14 nm。 Airmont 于 2015 年推出,是Silvermont的缩小版。
- DTLB 表大小加倍(128 个条目 -> 256 个条目)
- L2 延迟增加
- 重新排序缓冲区增加(从 32 个条目增加到 48 个)

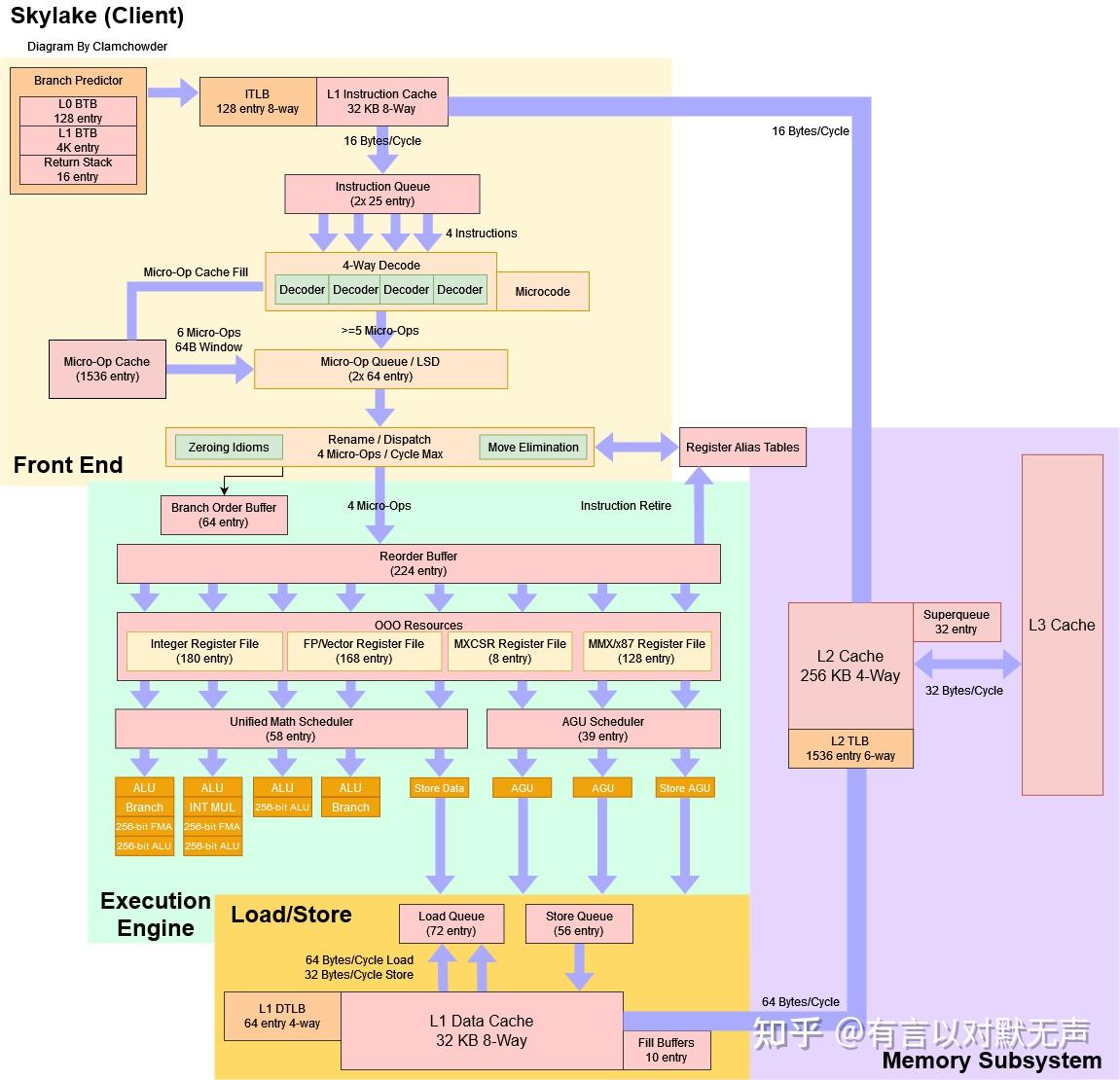
Skylake , 2015 年推出
Skylake基于14 nm。Skylake 接替了短命的Broadwell,后者经历了严重的延误。 该微架构由英特尔位于以色列海法的研发中心开发。
- 更宽的分配路径(从Broadwell的 4 路增加到 5 路)
- 微指令缓冲区/循环队列的每个线程的容量增大 2.28 倍(64 /线程,原 56 /核)
- 为每个活动线程的调度队列进行分区
- 改进的分支预测单元,准确率小幅度提升
- 减少直接跳跃目标的错误惩罚
- µOP 缓存指令窗口现在为 64 字节(原 32 字节)
- 1.5 倍带宽(从 4 增加6 µOP/周期)
- 更大的重新排序缓冲区(224 个条目,高于 192 个)
- 更大的调度程序(97 个条目,高于 64 个)
- 更大的整数寄存器文件(从 168 个增加到180 个条目)
- 更大的退休宽度(4 µOPs/周期/线程,从 4 µOPs/周期/核心)
- 更大的存储缓冲区(从 42 个增加到56 个条目)
- L2$从 8 路组关联更改为 4 路组关联
- 页面拆分加载损失减少 20 倍
- 更大的回写缓冲区
服务器版本支持AVX512。
- Skylake代表了Haswell的演进。Haswell已经是一个非常强大的架构,在其生命周期内没有遇到严重的竞争。Haswell核心具有良好的平衡性,几乎没有弱点,并且具有非常强大的向量执行能力。Skylake在这个基础上进行了改进,使其稍微更好一些。
- Haswell的比较:
- 前端:分支预测器
- CPU的分支预测器负责准确快速地生成指令获取地址。分支预测器对性能影响很大,工程师通常会在每一代中进行微调。Skylake的分支预测器行为很像Haswell的。这并不一定是坏事,因为在2010年代中期,Haswell已经拥有了最好的分支预测器。
- Skylake的分支预测器行为很像Haswell的。
- 前端:指令获取
- 一旦分支预测器生成了获取地址,前端就必须获取指令并为重命名器提供解码后的微操作。Skylake的指令获取和解码设置比Haswell更宽更深。L1i缓存和解码器之间的指令字节缓冲区从Haswell的每个线程20个条目增加到Skylake的25个条目。
- 解码器的改进
- Skylake还改进了解码器,每周期可以发出5个微操作。然而,解码单元每周期只能处理4条指令,因此只有在一个指令解码成两个或更多微操作时,才能从解码器获得5个微操作。
- 执行单元的增加
- Skylake的端口布局类似于Haswell。有四个整数执行端口,两个通用AGU端口和一个仅存储AGU端口。其中三个整数执行端口(编号0、1和5)还处理浮点和向量执行。
- 后端:乱序资源
- 为了避免长延迟指令导致卡住,CPU使用乱序执行来继续搜索独立指令以保持执行单元忙碌。更深的缓冲区允许CPU在管线阻塞之前更进一步。
- 缓存和内存访问
- Skylake的内存层次结构几乎与Haswell的相同,至少在客户端实现上是这样。每个核心都有32 KB的L1数据缓存和适中大小的256 KB L2缓存来降低对L3的延迟。L3通过环形总线分布在环上,每个核心一个切片,并允许带宽随着核心数增加而扩展。
- 性能提升
- 性能提升并非完全归因于IPC提高。Skylake通过将电源管理、内存层次结构和存储子系统进行了微调,使之更适合更高的时钟速度和更高的SMT线程数量。
- 前端:分支预测器


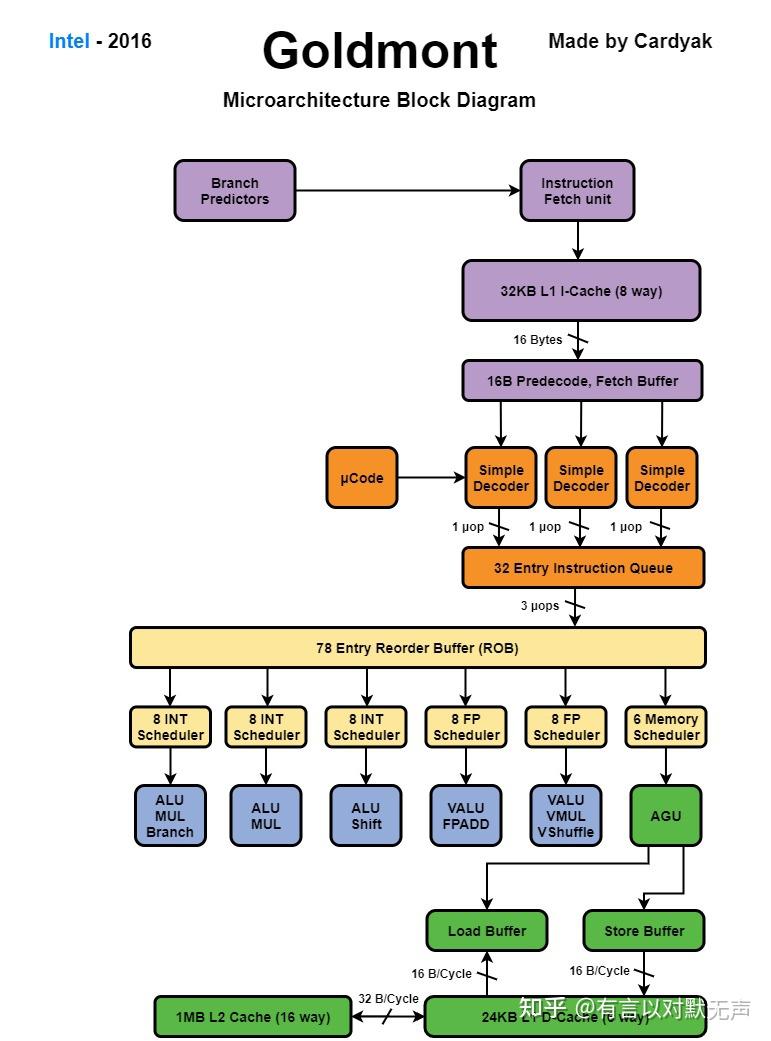
Goldmont , 2016 年推出
Goldmont 基于14 nm。 与 Airmont 相比,Goldmont 是一个 3 发射核心,提高了很多常用指令的吞吐量并减少延迟。

Goldmont Plus, 2017 年推出
Goldmont Plus基于14 nm。 与 Goldmont相比,也是一个 3 发射核心,
- 前端
- 增强的分支预测
- 后端
- 4路分配(原3路)
- 4路退休(原3路)
- 较大的发射队列
- 更大的ROB
- POPF延迟从约80个周期减少到约40个周期
- 向量除法和平方根更快
- AES操作:延迟从6个周期减少到4个周期,吞吐量增加到1个操作/周期
- SHL、SHR、SAR、ROL和ROR在CL中带有计数器:延迟从2减少到1
- 更宽的整数执行单元
- 新的专用JEU端口
- 支持更快的分支重定向
- Radix-1024浮点除法器,用于快速标量/压缩单精度、双精度和扩展精度浮点除法
- 改进了AES指令延迟和吞吐量
- 64 KiB二级预解码缓存(16 KiB起)
- 更大的负载缓冲区
- 更大的存储缓冲区
- 改进了存储到加载转发延迟从寄存器存储数据
- 新的STLB由指令和数据共享
- 分页缓存增强功能(PxE/ePxE缓存)


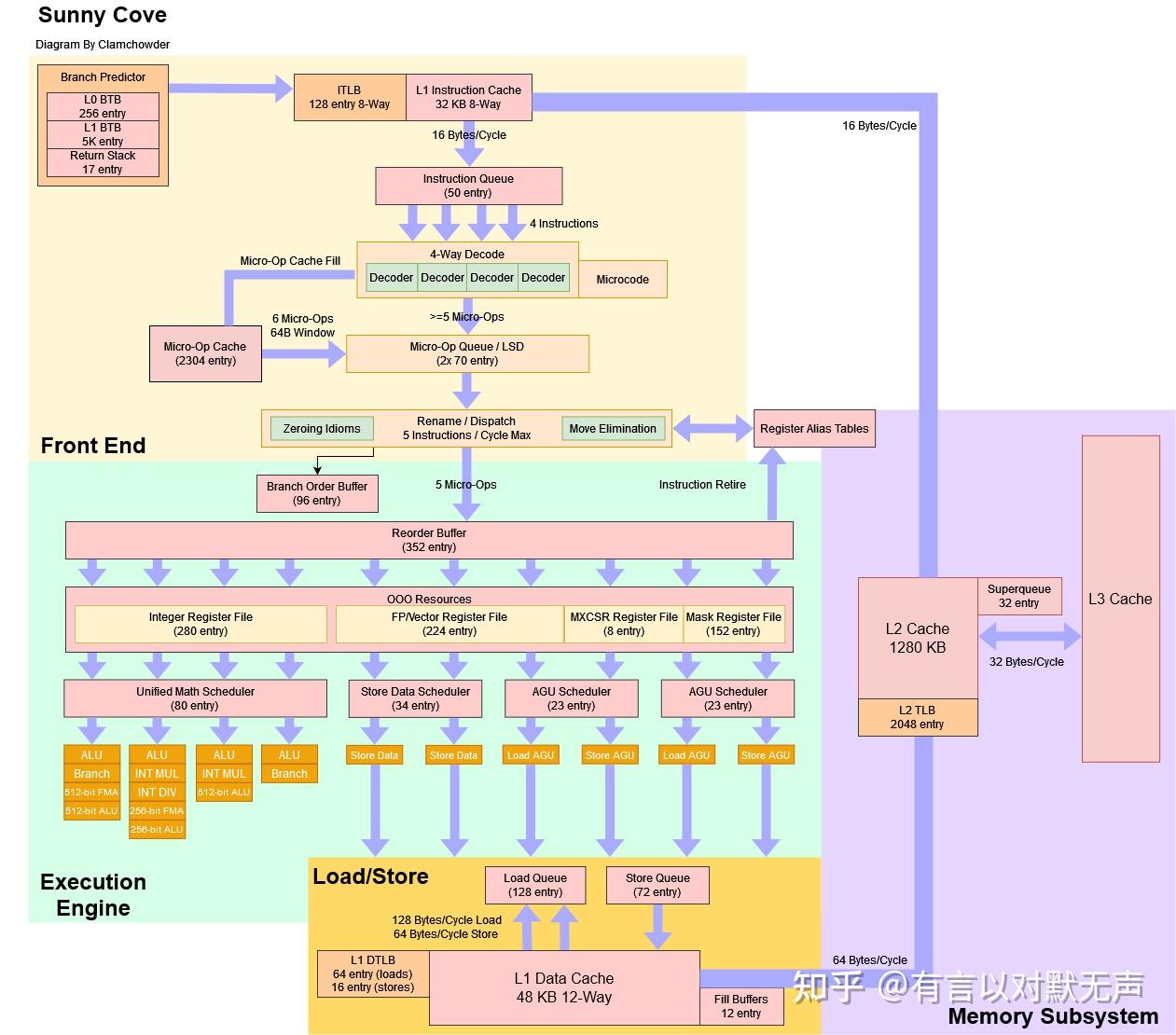
SunnyCove,2019年推出
10nm制程,类似Haswell的改进幅度,包含非常多的升级,是intel后续大核架构的起点。
- 与前一代相比,Sunny Cove有很大不同之处。
- Sunny Cove是一款高性能核心,具有非常深的乱序执行能力。
- 与从Haswell到Skylake的变化不同,Intel在几乎每个管道部分都对Sunny Cove进行了更改。
- 与其窄点相比,Sunny Cove为5宽,这是Intel十年来首次增加核心宽度,重命名器宽度从Skylake的4增加到了Sunny Cove的5。
- Skylake是一个更小的核心,仍然具有高性能,高时钟目标和非常好的ILP提取能力。
- 与Zen 2相比,Sunny Cove可以跟踪大约同样长的模式,但在处理大量分支时表现较差。
- Sunny Cove的分支目标跟踪比Skylake大,同时保持在2个周期的延迟。
- Sunny Cove的重命名IPC比Skylake和Zen 2都要高。
- Sunny Cove的乱序执行引擎更为强大,特别是在ROB、寄存器文件和调度器等关键结构上。
- Intel的大型联合式调度器一直是P6系列的一大特点。从Sandy Bridge开始,它是少数几个仍然可以追溯到P6的地方之一。
- Sunny Cove延续了这一趋势,并使用了更分布式的调度器。这使得总调度器条目数量增加了65%。
- Sunny Cove的前端也有显著变化。自Sandy Bridge以来,Intel首次增加了微操作缓存容量,从1.5K条目增加到2.3K条目。
WillowCove和CypressCove的一些小改动就不写了


Tremont,2019年推出
Tremont是Goldmont Plus的重大升级,它是一个性能与能耗兼顾的面向未来的设计。
- 重新设计的前端
- 新的双对称解码集群
- 乱序解码
- 6 宽解码
- 每个簇 3 路解码
- 更智能的预取器
- 改进的分支预测器
- 大核性能水平
- 更大的ROB
- 更宽发射端口(10 宽)
- 新的双对称解码集群
- 执行引擎
- 2 个存储数据端口(从 1 个增加)
- Tremont的乱序解码使得分支预测变得更加重要。幸运的是,Intel在选择“酷睿级高性能分支预测”时并非在开玩笑。
- 模式识别
- Tremont的模式识别能力与Skylake相似。虽然Tremont在预测延迟方面略有增加,但整体表现良好。
- 与Zen 1和Zen 2不同,Intel的L1预测器已经非常出色。
- 分支目标跟踪
- Tremont使用一个4096条目的分支目标缓冲区(BTB)来确定分支的去向。
- 在真实世界的分支预测性能方面,Tremont表现良好,与Golden Cove相比略有类似。
- 性能影响
- Tremont具有非常先进的性能监控功能,这可能暗示着intel会将该系列性能进一步拉高的想法。
- Intel的Tremont架构代表了Intel的Atom策略的变化,旨在涵盖低功耗、日常使用案例,并提高性能。
- 虽然分支预测器已经跟踪分支的去向,但如果分支之间距离过远,解码器将会像一个3宽度解码器,而不是6宽度解码器。
- Rename/Allocate
- Tremont的Rename和Allocate阶段作为前端和乱序后端之间的桥梁,但其Rename能力略弱于Skylake。
- Tremont的Rename器可以识别独立的MOV指令,但不能消除它们,这意味着它们仍然需要ALU端口。
- Scheduler and Execution
- Tremont使用分布式整数调度队列,拥有45个整数调度器条目,其中一部分用于处理分支指令。
- 与Zen 2相比,Tremont的调度器能力较低,但其灵活性略差。
- Cache and Memory Access
- Tremont的内存层次结构与Gracemont相似,但因专注于低功耗而较弱。
- L1D和L2缓存的延迟相同,但Tremont的L2较小,且L3的实际延迟较高。
- 总结
- Tremont的优势包括高吞吐量、高分支预测准确性和低功耗。
- 缺点包括小型整数调度器、缺乏AVX支持和较弱的内存子系统。
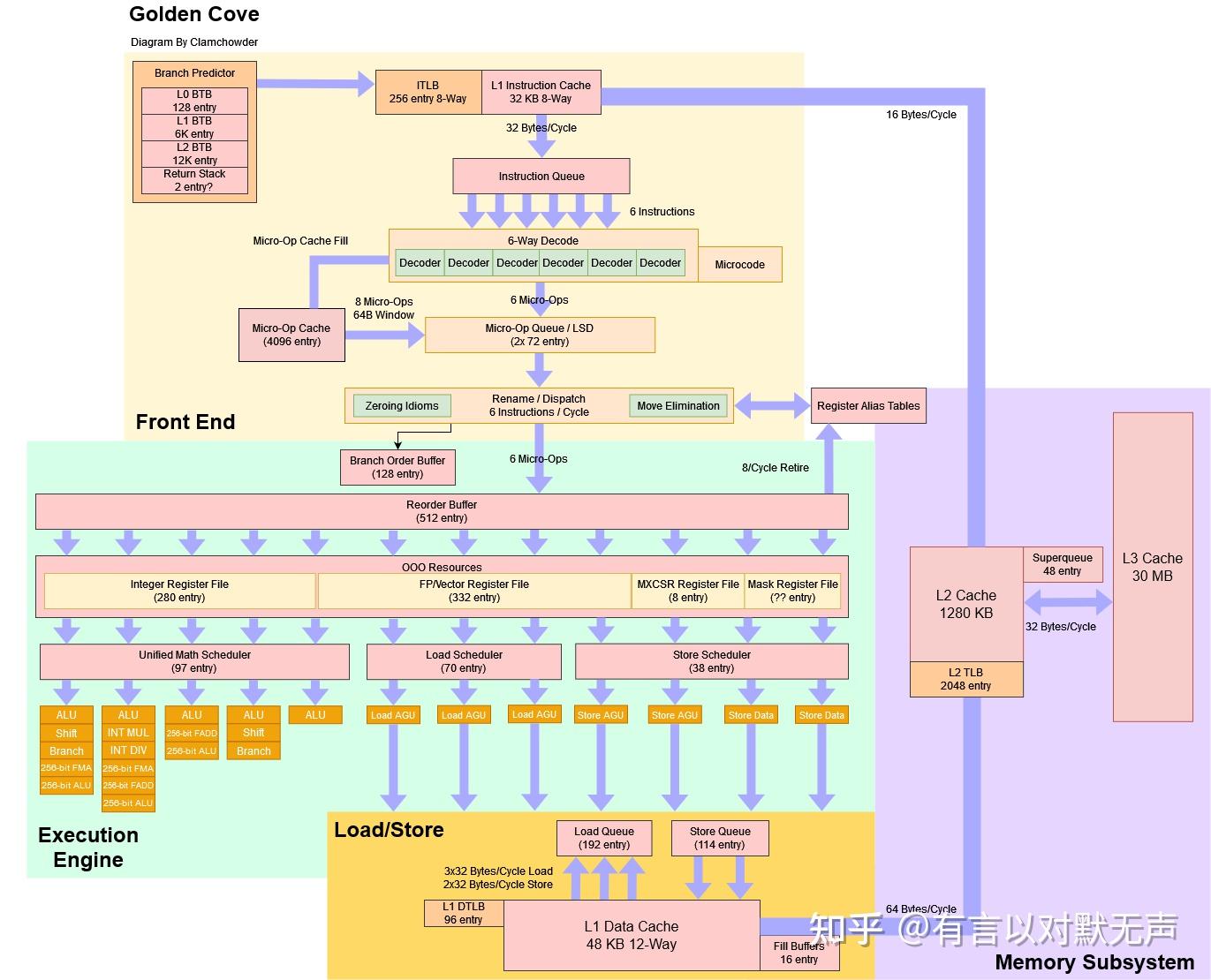
Golden Cove,2021年推出
- 从SunnyCove的 1+4 个简单解码器中置换1个复杂解码器,添加 1 个简单解码器,取消了复杂解码器设计,因为它不再实用,复杂指令现在可以通过MSROM中的宏指令融合独立处理,现在总共有 6 个简单解码器。
- 尽管差距不是很大,但Intel显然对Golden Cove的分支预测算法进行了调整。
- 与Zen 2相比,Golden Cove在一个分支的情况下大致相当(排除Zen 2的巨大L2 TAGE预测器覆盖惩罚)。
- Intel为Golden Cove配备了一个巨大的BTB。Golden Cove的预测器表现非常出色,大部分情况下位于Zen3和Zen4之间,但对于很长的分支识别能力不如Zen3。
- 它的重命名能力在所有6宽核心中最强。
- Golden Cove的重新排序缓冲区比Sunny Cove大了惊人的45%。
- Golden Cove的整数寄存器文件看起来并没有比Sunny Cove大。
- Golden Cove在纯整数负载中可能会在使用其引人注目的512个条目ROB之前耗尽整数寄存器而受到限制。
- Golden Cove的浮点单元位于三个端口后,这是对之前Intel架构的改进。
- Golden Cove可以通过两个周期延迟进行浮点加法。
- Golden Cove的矢量整数乘法器的延迟为10个周期。
- Golden Cove可以每周期进行两次512位加载。在每个内存控制器上,Golden Cove是一个带宽怪物。但 - Golden Cove在L3方面只保持了带宽优势,延迟控制较弱。
RaptorCove这种小改动就不列举了。
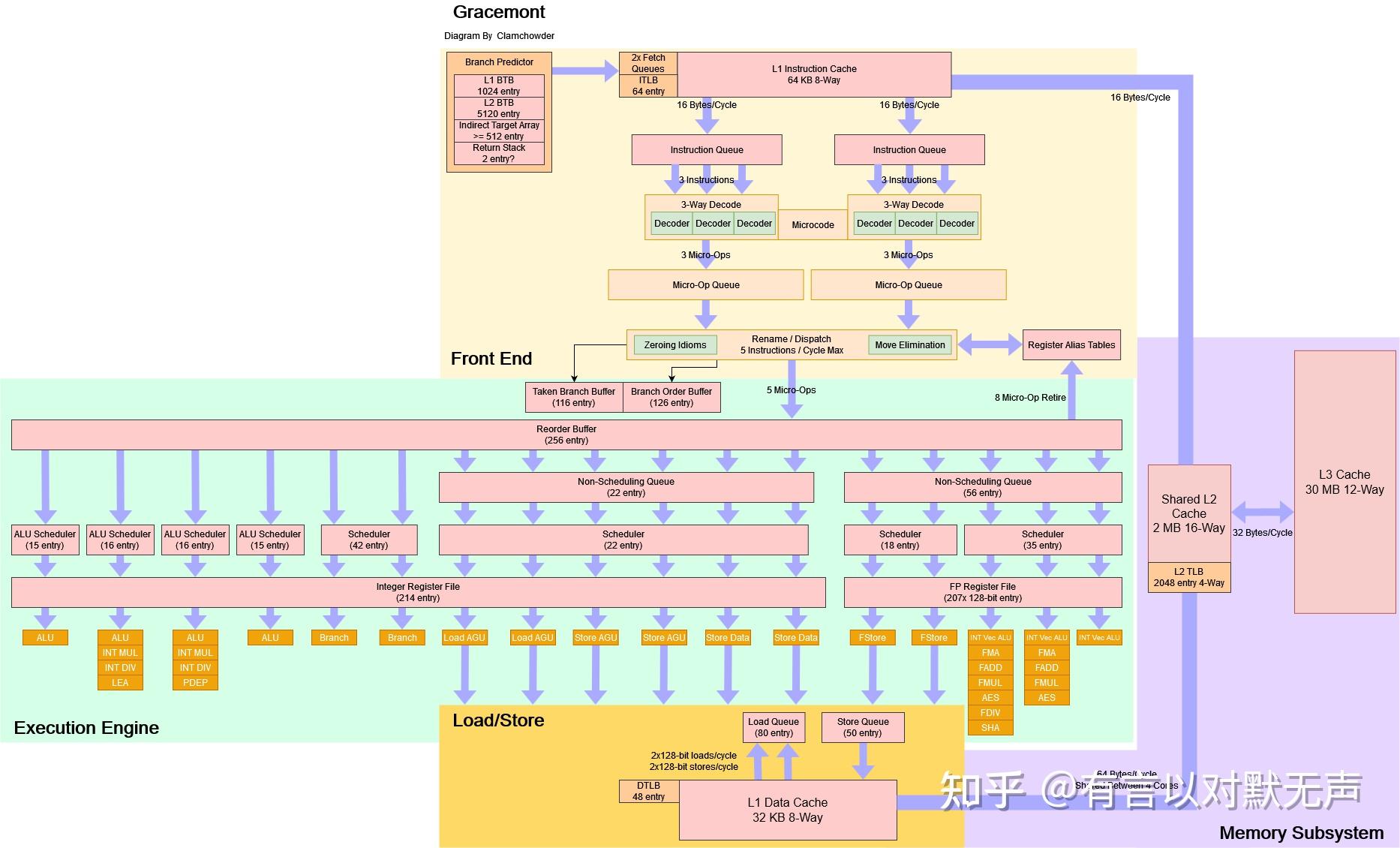
Gracemont,2021年推出
添加了一个OD-ILD(按需指令长度解码器),提高了分支预测和解码吞吐量。
- Gracemont是一种5宽度的乱序架构,其根源可以追溯到2013年的Silvermont。
- 英特尔的顺序Atom内核也可以被视为遥远的亲戚。
- Gracemont是英特尔Atom系列的新成员,它也是对以前的Atom系列架构的巨大改进之一,与早期的Atom完全不同,基本上是一个高性能核心。
- 它可能比Golden Cove小,但仍具有乱序执行和大的重新排序窗口。
- Gracemont的分支目标跟踪(BTB)可能看起来比Golden Cove的小,但与Sunny Cove和Zen 3相当。
- 与Zen 3类似,Gracemont可以进行零泡预测,最多可达1024个分支,但L2 BTB增加了两个周期的延迟。
- Gracemont具有类似于Zen 2的移动消除能力,这非常强大,并且超过了英特尔旧的同级别大核心,skylake。
- 除了显而易见的权衡之外,它没有任何严重的弱点。
- Gracemont的L3访问延迟高,带宽低,但这些牺牲都经过深思熟虑,不太可能影响常见的整数负载。
- 它是一个宽核心,具有深度的重新排序容量和与几年前桌面核心相近的时钟速度。
- Gracemont的执行吞吐量和容量看起来更像是高性能桌面核心,而不是旧的Atom。
- Gracemont在能效、密度和效率方面有着很大的优势,可以说是英特尔在超大规模服务器市场的入场券。
2023年的Crestmont的改进是分支预测,其它部分似乎没有变化
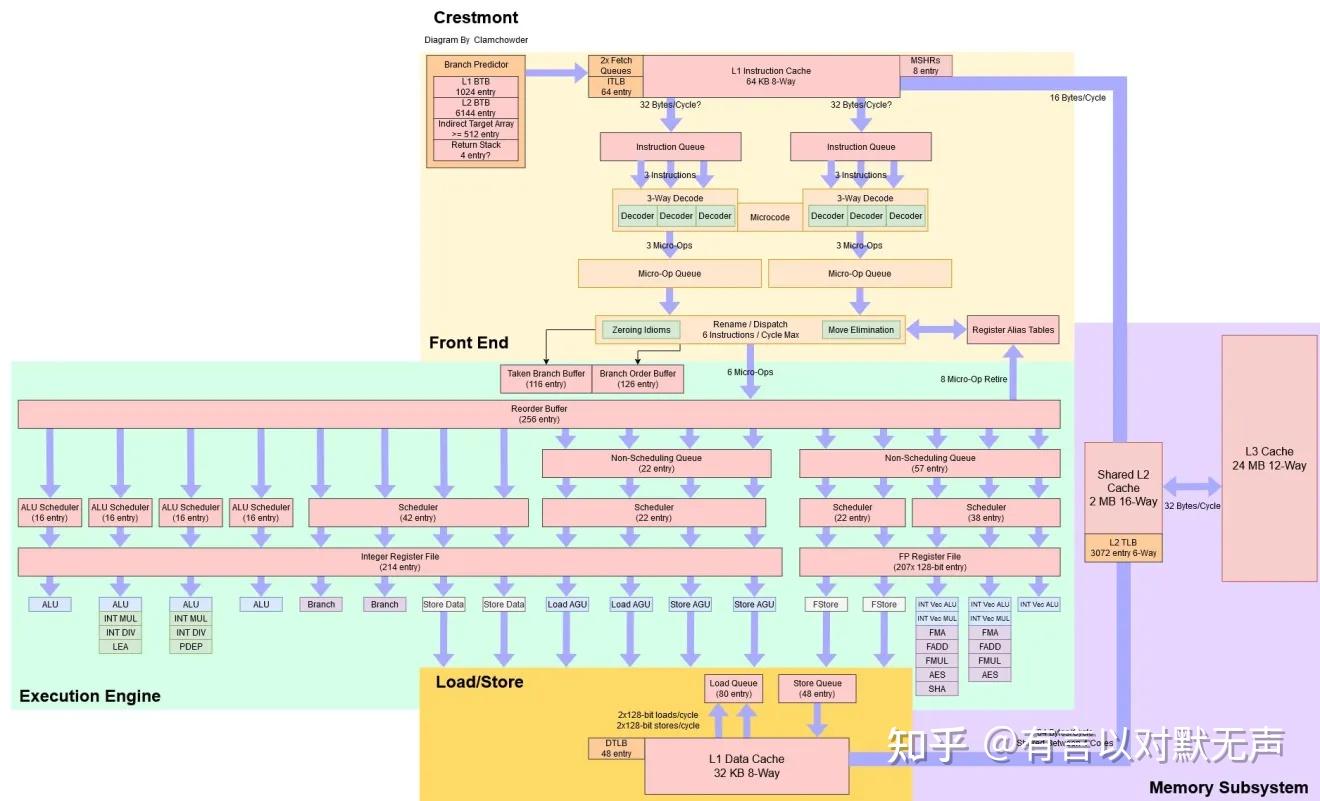
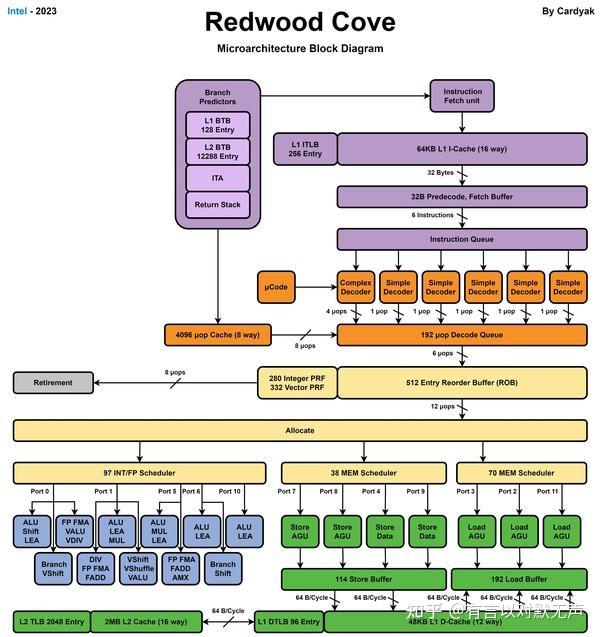
Redwood Cove ,2023年推出
L1 ICache的容量翻倍,其余其它部分似乎没有变化。