VIA/Zhaoxin CPU 微架构的演进
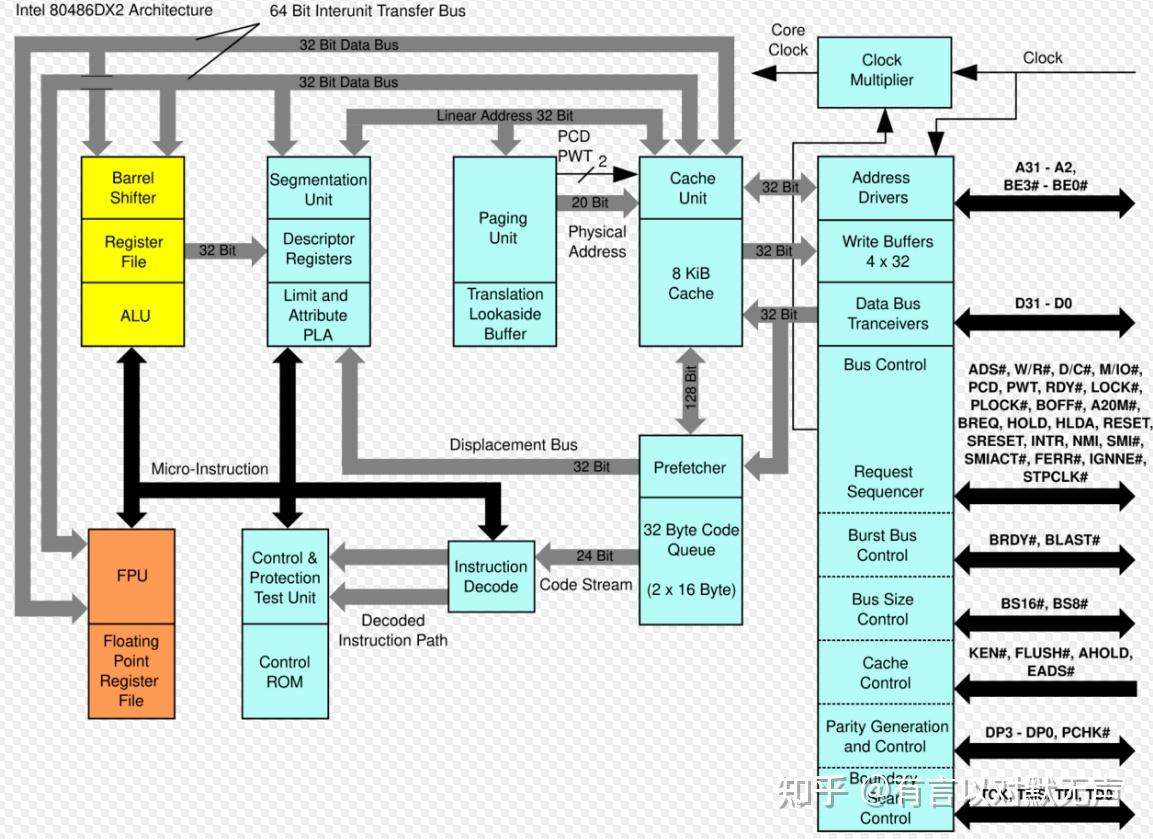
80486,1993年推出
Intel的80486是所有486和586的祖宗。
与其前身一样,80486与所有以前的x86处理器(80386、80286、80186等)保持了完全向后 的目标代码可比性。为了提高性能,英特尔引入了新的片上缓存层(之前存在各种外部扩展)。 8 KB、4 路组关联、回写策略高速缓存对于数据和指令都是一致的。这提供了对最近使用的数据和指令的更快访问。总线接口还进行了各种增强,包括需要单个时钟周期而不是多个时钟周期的更快通信。
而在使用单独封装的数学协处理器(即80387、80287等)之前,80486 将单元移至芯片上,完全消除了外部通信延迟。此外,更先进的数学算法被用来实现新的FPU,从而产生更快的浮点计算。
- 1992年,Cyrix推出了其第一代CPU, 486SLC和486DLC,旨在与英特尔的486SX和486DX竞争。它们还与386SX和386DX管脚兼容,这意味着它们可以作为老化的386主板的直接升级,制造商也用它们来销售廉价笔记本电脑。32位芯片,有1KB的L1缓存,性能都略低于英特尔486 CPU。
80486是Intel80486系列微处理器的微架构,是80386的后继产品。 89 年 4 月推出的 80486 最初采用1 µm 工艺(后来为800 nm)制造。对于 Cyrix这种微架构用于其Cy486系列。
Cy5x86,1995年推出
- Cyrix 于 1995 年 8 月推出了 5x86 处理器,是一款插槽为 3.3V 486 socket 的处理器,运行速度可达 80、100、120 或 133 MHz,性能与 Pentium 75 MHz 相当。填补了市场上其他处理器未能覆盖的功能空缺。
- Cyrix 在 1995 年晚些时候发布了其最著名的芯片 Cyrix 6x86 (M1),继续了 Cyrix 更快地替代 Intel 设计插槽的传统。它拥有5x86 核心特性:超流水线微架构,但不是超标量微架构,16 KB 一级写回缓存,集成浮点单元,分支预测以及能够并行执行浮点指令和整数指令。而 6x86 的推出也使得 Cyrix 在市场中有了更广泛的影响力,尽管它的处境并不容易。
- 6x86 处理器延续了 Cyrix 的传统,更快地替代英特尔设计的插槽。6x86 是该系列中的明星产品,据称其性能比英特尔“同等产品”有所提升。 6x86 处理器被命名为 P166+,表明其性能优于 Pentium 166 MHz 处理器。但 6x86 的浮点协处理器并不像 Intel Pentium 中的那样快。
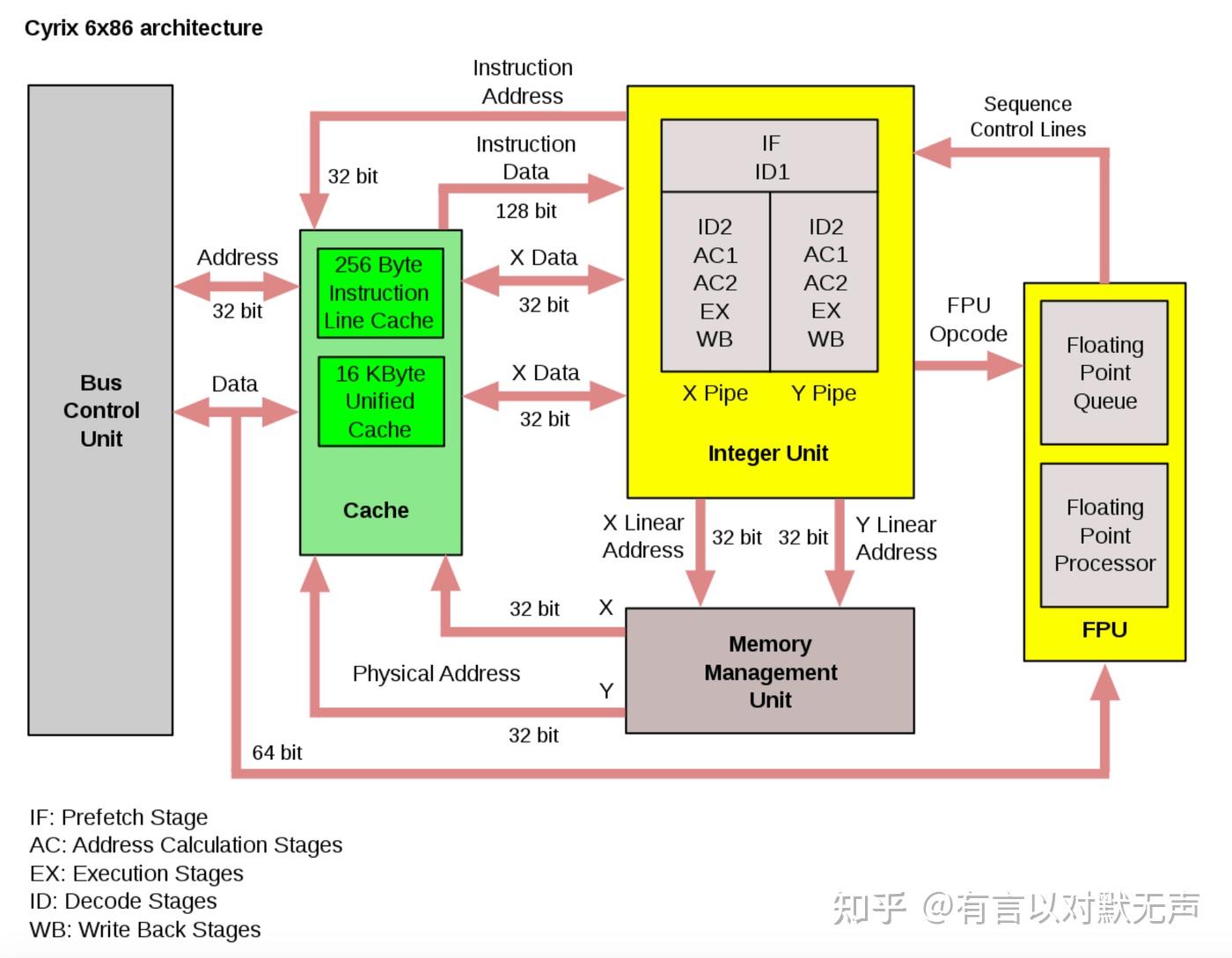
- 后来的6x86L是经过修改的6x86,功耗更低,6x86MX(M2)增加了MMX指令和更大的L1缓存。CyrixMII基于 6x86MX 设计,只不过是个换皮,旨在帮助该芯片从营销上更好地与Pentium II竞争。
- 1997年,Cyrix发布了核心代号为M2的「6x86MX」,最大的区别是内置了MMX指令集。
- Cyrix 于 1996 年推出了 MediaGX CPU,集成了 PC 的所有主要组件,包括声音和视频,运行速度为 120 或 133 MHz。MediaGX 使得 Cyrix 在低端市场取得了成功,例如 Compaq 的 Presario 2100 和 2200 电脑。
- Cyrix Media GXi 是 Cyrix 于 1997 年发布的版本,用于移动计算市场,集成图形和音频控制器,适用于小型笔记本电脑。
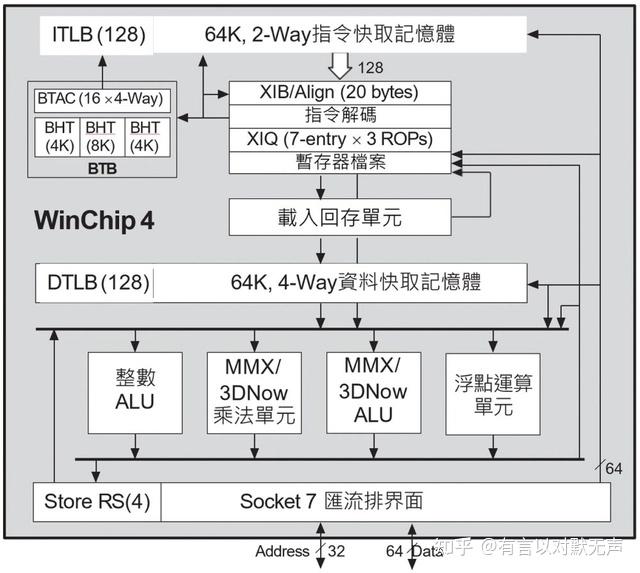
WinChip,1997年推出
- WinChip系列是基于Socket 7的低功耗x86处理器,由Centaur Technology设计,由IDT销售。
- 它的设计与其他处理器有很大不同,利用RISC处理器市场经验创建了类似于80486的高能效处理器。
- WinChip比竞争对手(如AMD K5/K6)简单得多,因为它具有单宽度流水线和顺序执行微架构。
- 它适用于很少进行浮点计算的流行应用程序,包括当时的操作系统和企业软件。
- WinChip被设计为直接替代更复杂昂贵的竞争对手处理器,利用Intel的Socket 7系统平台。
- WinChip 2(C6+)是C6的更新版,保留了简单顺序执行管道,但添加了双MMX/3DNow!处理单元。C6+ 添加动态分支预测(4096 个单位元分支历史表)
- WinChip 2A增加了小数乘法器,采用100 MHz前端总线以提高内存和L2缓存性能。
- 它的性能类似于当代AMD和Cyrix 486处理器。
- WinChip 2B是修订版,芯片尺寸缩小至0.25μm,但出货量有限。
- 第三种型号WinChip 3原计划具有双倍L1缓存,但未上市。
- IDT声称C6与Pentium MMX在整数性能方面相当,但浮点和MMX单元性能不及Pentium MMX。
- WinChip C6针对低端市场,类似于AMD K6和IBM/Cyrix 6x86MX的低时钟版本。
- IDT计划将C6时钟速度提高到400 MHz,并在笔记本电脑中使用低功耗。
- C6的架构不如竞争对手复杂,使用大型L1缓存和经典微处理器设计。
- WinChip C6的制造成本较低,但市场份额有限。
- WinChip C6与Intel Pentium和Pentium MMX、Cyrix 6x86以及AMD K5/K6竞争,性能仅适用于少数使用浮点数学的应用程序。
- 浮点性能低于Pentium和K6,甚至比Cyrix 6x86慢。
- 1999年,IDT的Centaur Technology部门被出售给VIA,标志着WinChip的终结。
- Winchip C6采用0.35微米4层金属CMOS技术,支持MMX,具有64 Kib L1高速缓存。
- WinChip 3 的 128 Kib L1 高速缓存使用 64 KB 2 路组关联代码高速缓存和 64 KB 4 路组关联数据高速缓存。支持MMX和3D Now。
Cayenne ,2000 年推出
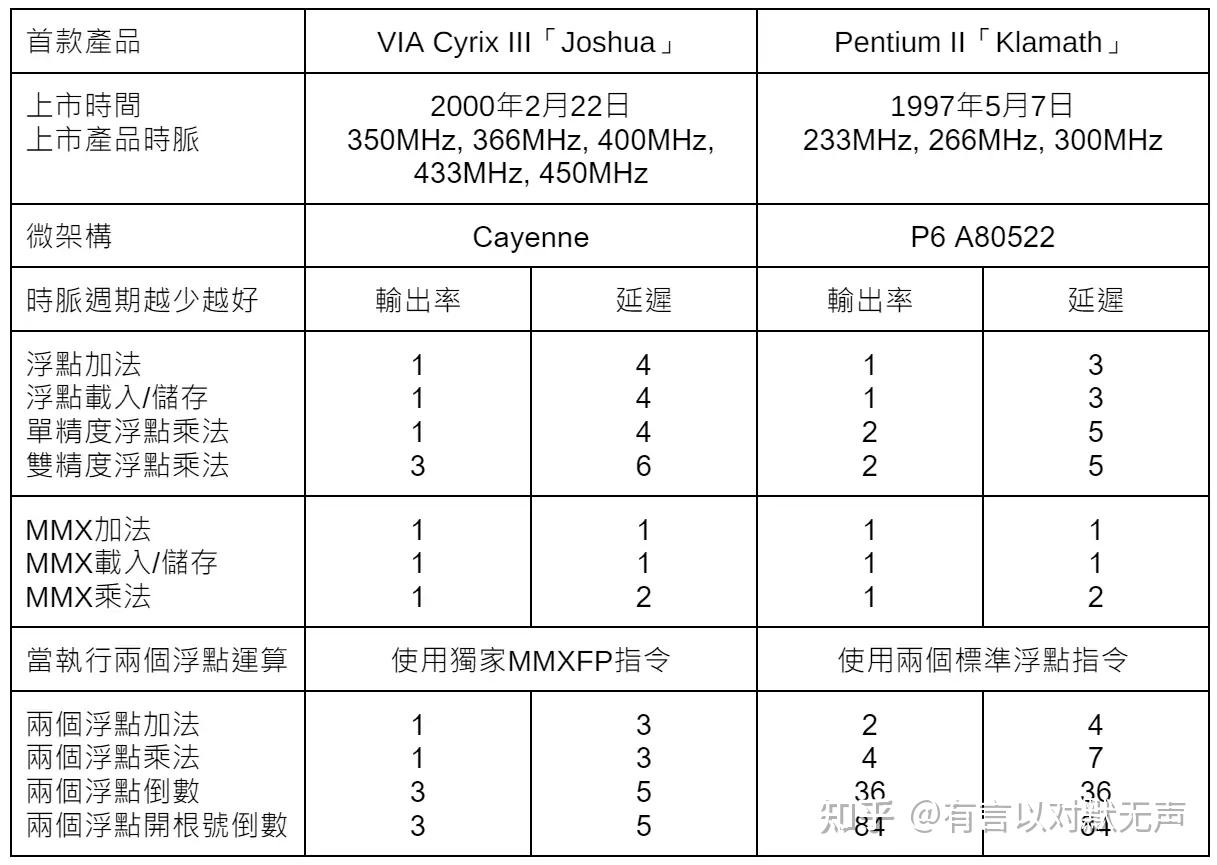
Cyrix 开发的 Cayenne 微架构是 6x86MX/MII 处理器的演进版,具有双路 FPU、支持 3DNow 指令和64KB L1 和 256 KB、8-way L2 缓存。它使用在VIA Cyrix III /Joshua(后来更名为 C3)中,具有2200 万个晶体管。
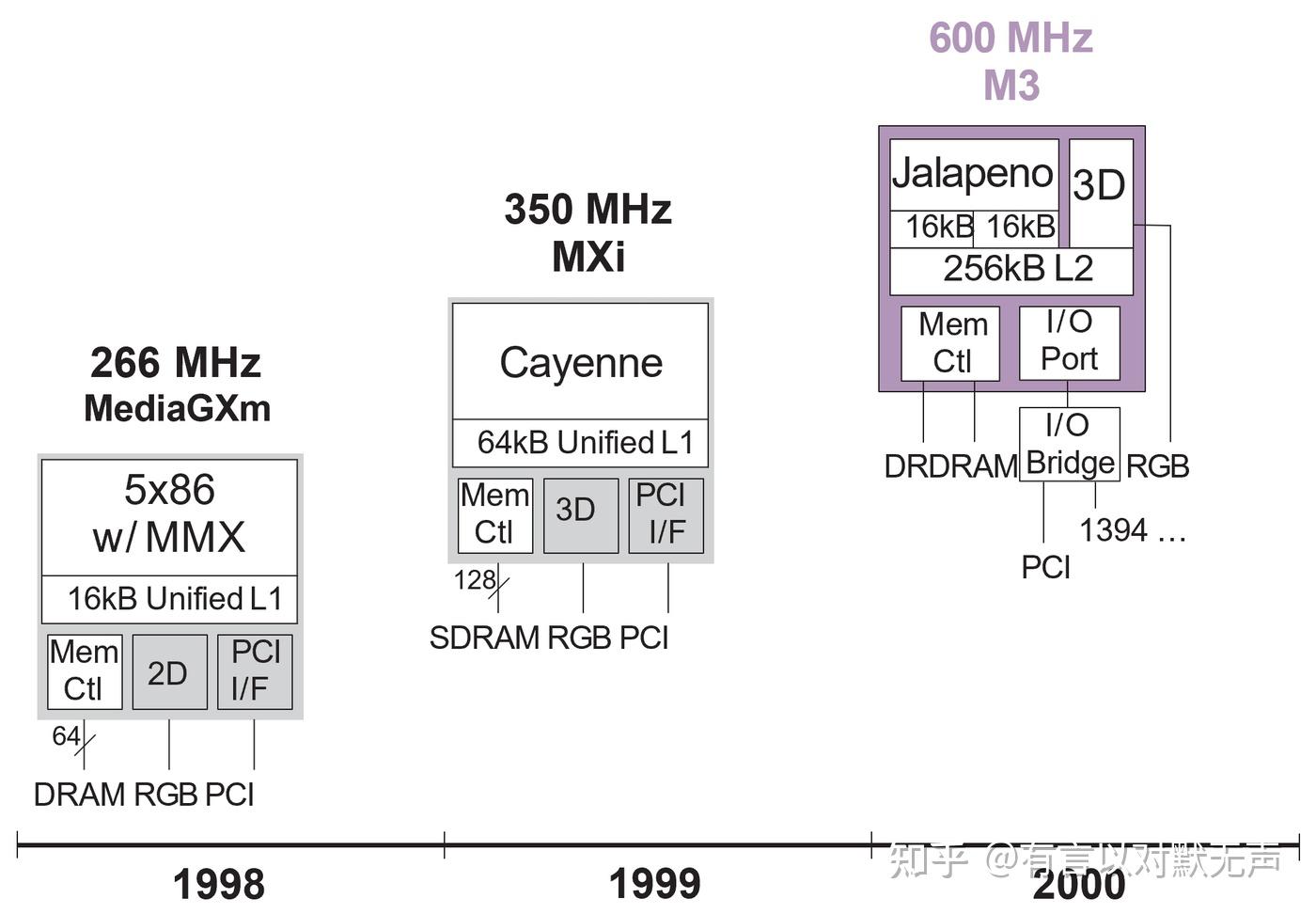

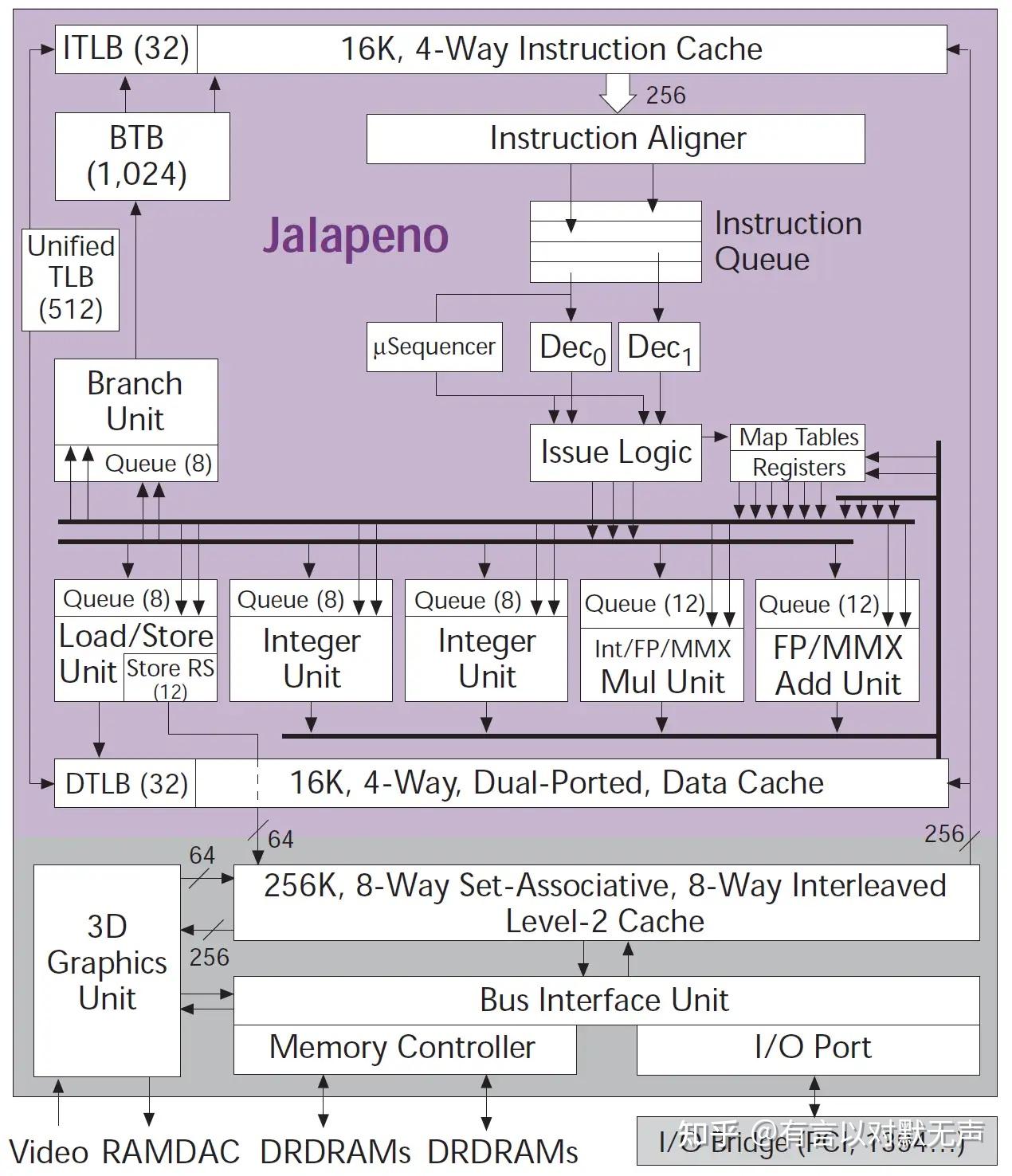
Jalapeno ,2000 年推出
Cyrix废弃的2宽乱序核心设计,可能对后续VIA的乱序核心设计起到了一定影响。
Samuel,2000 年推出
- VIA采用了Centaur Technology设计的1100万晶体管Samuel核心,相比Joshua核心在功耗、尺寸和性能方面有所改进。
- Samuel核心是WinChip处理器的演变,专为更高时钟速度设计,拥有更多L1缓存但没有L2,并采用更小制造技术。
- 该版本的Cyrix III虽然性能仍低于竞争对手,但非常节能,仅包含Cyrix创建的晶体管数量的一半。
- Samuel2在Samuel核心的基础上增加了64KB二级缓存,并将制程缩小至 0.15 微米,使得性能提升,使得核心尺寸减小40%,尽管性能仍落后于竞争对手。
- Cyrix III还包含MMX和3Dnow!优化,具有与流行AMD K7处理器有相同的12 级流水线。
- Samuel2采用更小制造技术,具有大型一级代码和数据缓存,但没有二级缓存,且设计更为简单。
- Samuel2的总线速度与原始Samuel内核相同,采用100和133 MHz总线速度运行,落后于AMD Duron的100 MHz DDR总线速度。
- VIA C3(原VIA Cyrix III)基于Samuel2核心发布,采用0.15微米技术制造,具有较低功耗和价格。
“Ezra”(C5C)和“Ezra-T”(C5N)只是“Samuel 2”内核的新版本,对“Ezra-T”的总线协议进行了一些小的修改,以匹配与英特尔奔腾III“Tualatin”的兼容性核心。威盛多年来一直在 x86 CPU 市场上保持着最低的功耗。然而,由于设计缺乏改进,性能落后。
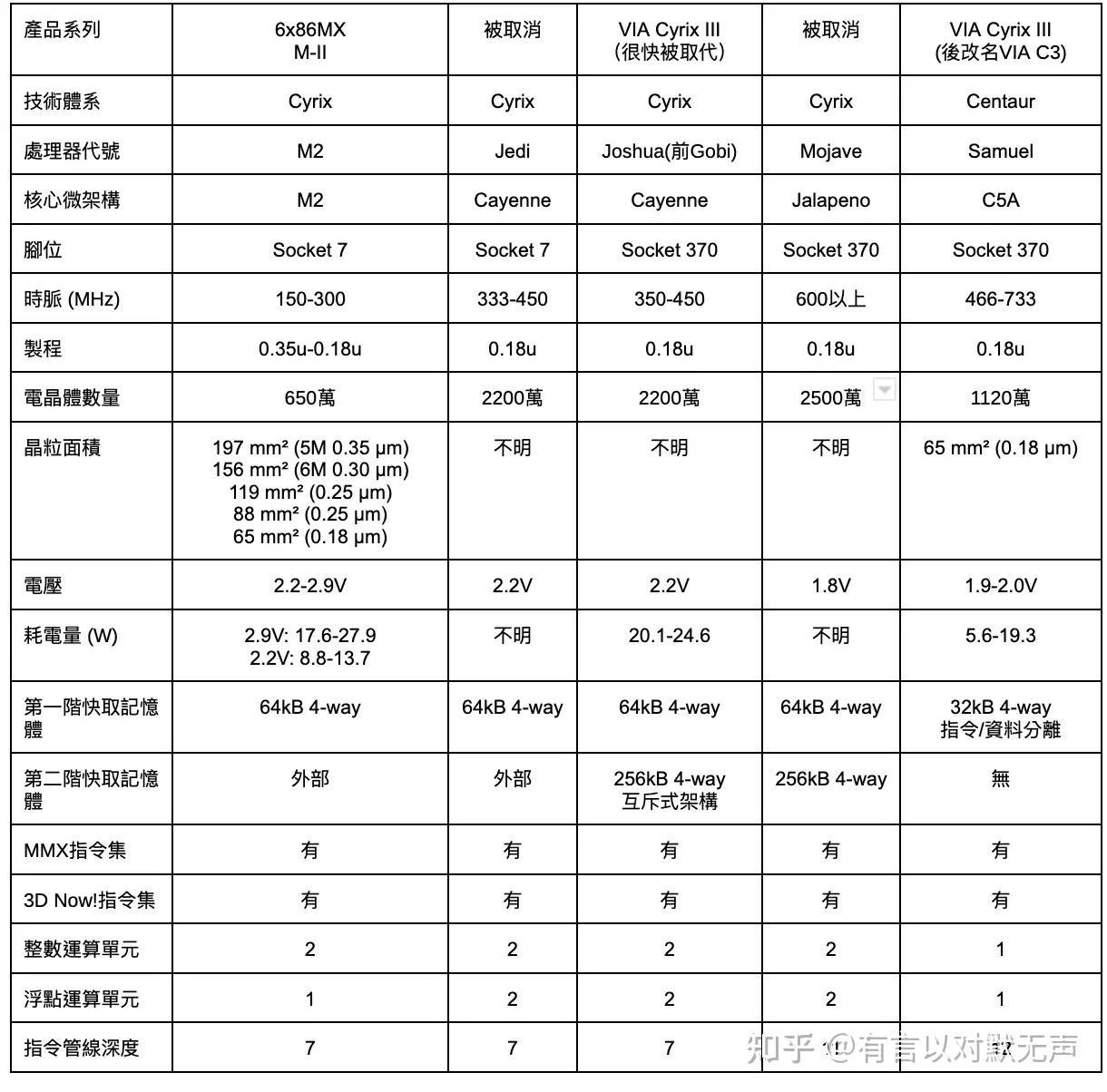
Nehemiah,2001 年推出
Nehemiah 核心
- “Nehemiah”(C5XL)是一次重大的核心修订。解决了旧核心的许多设计缺陷,包括半速 FPU。流水线级数从 12 增加到 16,以允许继续提高时钟速度。此外,它它还移除了 3DNow! 指令,改为支持 SSE 指令、AES 加密和随机数生成器、还实现了 cmov 指令,使其成为 686 级处理器。Linux 内核将此核心称为 C3-2。。但它仍然基于老旧的 Socket 370,以只有 133 MHz 的单数据速率前端总线运行。
- 嵌入式系统市场更倾向于低功耗、低成本的 CPU 设计,因此威盛开始更积极地针对这一细分市场,因为 C3 符合这些特点相当好。Centaur Technology 专注于增加嵌入式市场吸引力的功能。
- “Nehemiah+”(C5P)(步进 8)修订带来了一些进步,包括高性能的 AES 加密引擎,以及一个尺寸显著小的球栅格阵列芯片封装。同时,威盛将 FSB 提升至 200 MHz,并推出了新的芯片组,如 CN400 来支持它。新的 200 MHz FSB 芯片仅在 BGA 封装中提供,因为它们与现有的 Socket 370 主板不兼容。
- 由于内存性能是许多基准测试的限制因素,VIA 处理器实现了大型主缓存、大型TLB和主动预取等增强功能。虽然这些功能并非威盛所独有,但内存访问优化是他们没有放弃功能以节省芯片空间的一个领域。
- 该流水线旨在为 x86 指令的大量使用的寄存器-内存和内存-寄存器形式提供单时钟执行。与其他 x86 处理器相比,一些常用指令需要更少的频率。
Esther,2005 年推出
- Esther(C5J/C7)是VIA C3系列的Nehemiah+(C5P)核心的下一个演进步骤。
- 平均功耗低于1瓦特。
- 2 GHz操作频率和20瓦特的TDP。
- L2缓存从64k增加到128k,关联性从C3的16路组关联增加到C7的32路组关联。
- VIA表示C7总线在物理上基于Pentium-M 479引脚封装,但使用专有的VIA V4总线进行电气信号传输,避免了法律侵权。
- “双涡轮”技术,包括双PLL,一个设置在高时钟速度,另一个设置在较低时钟速度。这使得处理器的时钟频率可以在单个处理器周期内调整。
- 支持SSE2和SSE3扩展指令。
- 在PAE模式下的NX位,防止缓冲区溢出软件漏洞被病毒或攻击者利用。
- 硬件支持SHA-1和SHA-256哈希、RSA 加密。
- 加密硬件基于“Montgomery乘法器”,支持最多32K的公钥加密密钥尺寸。
- C3系列芯片设计理念的核心是,即使是相对简单的有序标量核心,如果有高效的“前端”支持,即预取、缓存和分支预测机制,也可以提供合理的性能,抵抗复杂的超标量无序核心。
- 对于C7,设计团队专注于进一步精简芯片的(前端),即缓存大小、关联性和吞吐量以及预取系统。
- C7成功地缩小了与AMD / Intel芯片性能之间的差距,因为时钟速度不受热量约束。
- 凭借其超低功耗,威盛 C5J Esther 内核面向智能数字设备,将 x86 架构的应用范围进一步扩展到消费电子、嵌入式和移动领域,超出当前处理器性能和热限制所允许的范围。
Isaiah,2008 年推出
- 2009年11月3日,VIA推出了Nano 3000系列。
- 2011年11月11日,VIA发布了首款双核pico-itx主板的VIA Nano X2 Dual-Core Processor。
- 2014年起,兆芯处理器基于VIA Nano系列。
- 代号“CN”由Centaur Technology在美国使用,代号为圣经名字的台湾代号由VIA使用。
- 预计VIA Isaiah在整数性能上将是上一代VIA Esther的两倍,浮点性能将是四倍。
VIA Isaiah的架构概述
- x86-64指令集
- 时钟速度从1 GHz到2 GHz
- 533 MHz或800 MHz的总线速度(Nano x2为1066 MHz)
- 每个核心64 KB数据和64 KB指令的L1缓存和1 MB L2缓存。
- 65 nm制造工艺(Nano x2为40 nm)
- 超标量乱序指令执行
- 支持MMX、SSE、SSE2、SSE3、SSSE3和SSE4指令集
- 支持Intel兼容实现的x86虚拟化(在步进3之前禁用)
- 支持ECC内存
- 与VIA C7和VIA Eden兼容
- 乱序和超标量设计:比VIA C7处理器更好。
- 指令融合:将多个指令合并为单个指令,提高性能,减少功耗。
- 改进的分支预测:使用两个管线阶段中的八个预测器。
- CPU缓存设计:独占缓存设计意味着L1缓存的内容不会在L2缓存中重复,提供更大的总缓存。
- 数据预取:包括数据预取的新机制,包括在加载L2缓存之前加载特殊的64行缓存和直接加载到L1缓存。
- 每四个周期获取x86指令,而不是英特尔的三到五个周期。
- 多种数据预取机制,将预取数据直接加载到L1或L2缓存中,或者加载到特殊的小型预取缓存中
- 拥有两拍的解码阶段,每周期可接收三条x86指令。
- 解码阶段可执行宏融合和微操作融合。
- 宏融合功能,可以将 x86 指令的某些组合合并为单个微操作(内部指令)。
- 微融合功能可以将两个或多个微操作合并为一个微操作。
- 每个时钟向执行单元发出三个微操作
- 存储器访问:将较小的存储合并到较大的加载数据中。
- 执行单元:提供七个执行单元,每个时钟可执行七个微操作。
- 两个整数单元(ALU1和ALU2)
- ALU1具有完整功能,而ALU2缺少一些低使用率指令,因此更适合任务,如地址计算。
- 两个存储单元,一个用于地址存储,一个用于数据存储。一个加载单元。
- 两个媒体单元(MEDIA-A和MEDIA-B),具有128位宽的数据通路,支持4个单精度或2个双精度操作。
- MEDIA-A执行浮点“加”指令(单精度和双精度2时钟延迟),整数SIMD,加密,除法和平方根。
- MEDIA-B执行浮点“乘”指令(单精度2时钟延迟,双精度3时钟延迟)。
- 由于引入了两个媒体单元的并行性,媒体计算每个时钟可以提供四个“加”和四个“乘”指令。
- 迄今为止x86处理器具有最低时钟延迟的FP加法的新实现。
- 几乎所有整数SIMD指令都在一个时钟周期内执行。
- 电源管理:除了需要极低功耗外,还包括许多新功能。
- 包括一个新的C6电源状态(刷新缓存,保存内部状态,并关闭核心电压)。
- 自适应P-State控制:在性能和电压状态之间进行转换,无需停止执行。
- 自适应超频:如果处理器核心温度低,则自动超频。
- 自适应热极限:调整处理器以保持用户预定义的温度。
- 支持AES加密,安全哈希算法SHA-1和SHA-256以及随机数生成。
- 分支预测有八个预测器,用于推测执行和分支目标确定。
- 解码后指令进入uop队列,再进ROB和保留站进行寄存器重命名。
- ROB+RS,每周期最多发出七条指令到七个执行单元。
- FP/矢量单元有强大的浮点能力,特点是对浮点加法速度快。
- 不支持内存消歧和存储合并。
- 缓存层次结构大,64K L1指令和数据缓存,1MB L2缓存,有数据预取缓存。
- 分支预测器设计复杂,使用4096条目的4路BTB。
- ROB有65个条目,有加载和存储队列,所有调度器总共有76个条目。
- 浮点寄存器文件有46个整数和48个SIMD/FP寄存器,加载/存储单元布局正常。
- 分支预测器性能同时期更好,但BTB巨大并带来高延迟。
- Isaiah的BTB相对Bobcat大很多,但速度略慢,有非常复杂的分支预测器和竞争预测方法,模式识别能力更强。
- Isaiah中的执行单元非常强大,而且执行延迟非常低。然而,也存在一些弱点:
- 未对齐的内存访问代价非常高昂。
- 存储转发仅在相对简单的情况下起作用。
- 数据高速缓存访问仅限于每个时钟周期一次读取或一次写入。只有极少数情况下它才能同时读写。
- 分支密度限制。每 16 字节代码仅限两次跳转或分支。当超过此限制时,性能会下降。
- 分支吞吐量。 Nano 每三个时钟周期只能进行一次分支或跳转。
- 当大多数指令进入 I1 和 I2 执行端口时,会出现次优排队。
- 在不同执行单元或子单元之间移动数据会产生许多额外的延迟。
- Nano 2000 和 Nano 3000 系列之间的主要区别在于执行单元。 Nano 3000 对于大多数整数指令有两个执行单元。它有一个新的整数乘法单元,具有 2 个时钟延迟。除法得到改进,SIMD 指令也有一些小的改进。未对齐的内存访问和存储转发有所改善,但仍然比更大的处理器效率低。
- Isaiah架构与其他CPU的比较:
- 拥有大型分布式调度程序和强大的执行引擎。
- FP/SIMD端口延迟低,性能接近Intel Core 2。
- 缓存结构与竞争对手有差异,L1D延迟短。
- Isaiah架构是VIA与AMD、Intel竞争的雄心勃勃尝试。
- Isaiah具有强大的执行引擎和分支预测器,但功耗相对高。虽然功耗较高,但Nano的性能仍有竞争力,尤其在多媒体应用方面。
- Isaiah架构代表了Centaur工程团队的能力和决心,但成功的关键在于架构的预测重要工作负载和资源分配。
- 与竞争对手相比,Nano具有一些优势和劣势,但对于特定应用场景仍具有价值。

Isaiah2,2015 年推出
Isaiah2也称为CNR架构,28nm制程
- Isaiah2 在原始 Isaiah 微架构上有所改进:
- 改进物理设计,实现更高的时钟速率
- 更大的L2缓存,1MB->2MB/Core
- 支持AVX2指令集,但需要3个执行端口才能完成,因此实际运行AVX2指令延迟很高
- 原生四核设计
Zhangjiang,2016 年推出
zhangjiang也称为ZX-C+,28nm制程,是Isaiah2的轻微修改版本
- 兆芯在CNR的基础上加入了中文哈希算法SM3、SM4进入Padlock加密模块,被称为 zxsm。
- 并且在物理设计上搞了两个die 共8核的胶水八核服务器KH-10000系列试验品
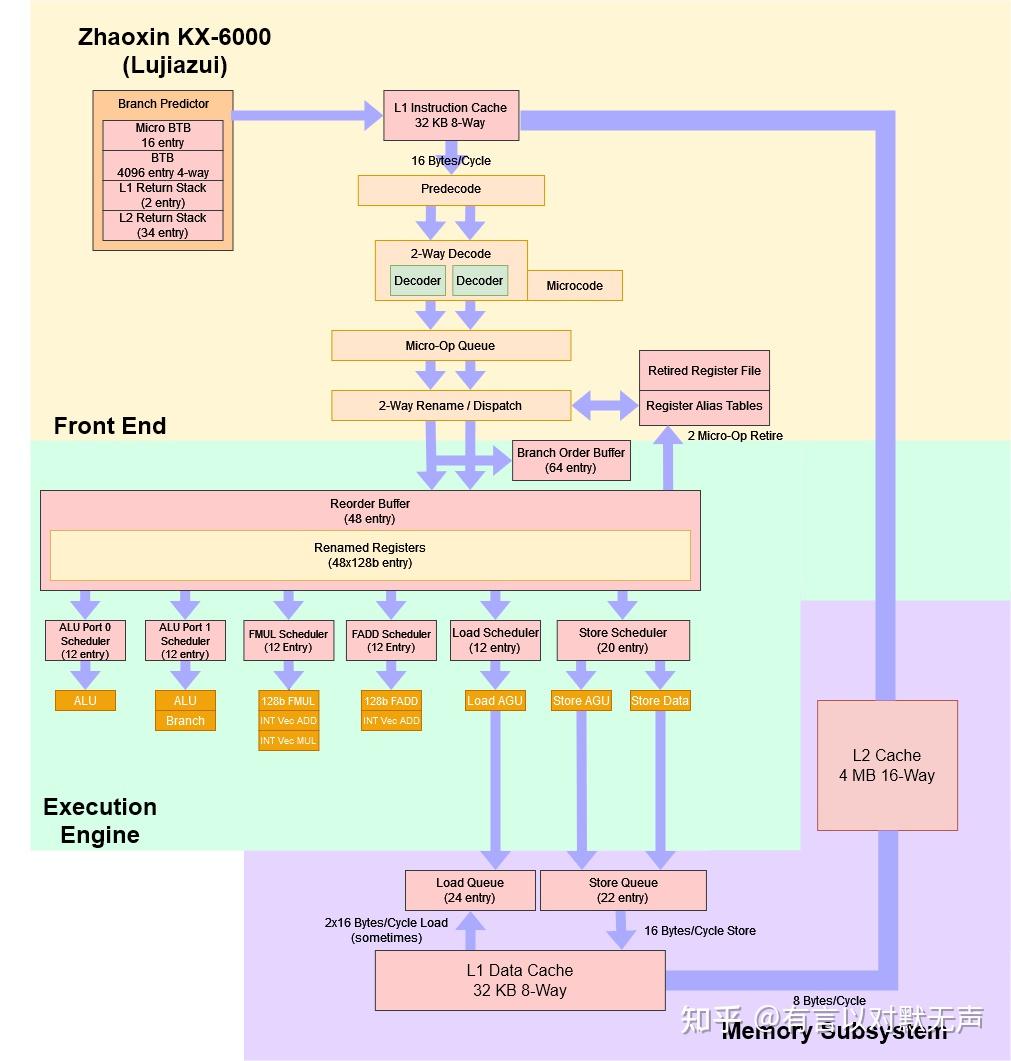
Wudaokou/Lujiazui,2018年推出
- 由于设计能力和时间不足,兆芯更关注能耗比和芯片面积。
- 五道口内存控制器支持双通道DDR4,速率最高2400 MT/s。
- 陆家嘴制程升级至16nm,CPU频率提升,内存控制器支持128GB,速率3200 MT/s。
- 五道口架构是个全新设计,集成8个x86核心,支持多达三个显示器,GPU支持DirectX 11.1和4K分辨率,使 - 用点对点高速互连总线。
- 分支预测优化:修改算法、增加循环预测器和指令队列,动态关闭前端取指和译码单元,优化预测错误带来的冲刷流水线惩罚。
-
缓存层次结构改进,内存控制器、调度器和分支预测单元优化,内核设计、分支预测和调度算法改进,针 - 对长延迟负载和分支进行重排。流水线深度优化对性能提升有显著影响。
- 陆家嘴与以赛亚架构对比:改进内核设计、分支预测和调度算法,内存控制器、分支预测和执行效率提升,ROB大小和调度器优化。
- 缓存层次结构优化与内核设计,分支预测、调度器和ROB的性能改进,内存控制器和高速互联总线的升级。
- 兆芯2016年申请的分支预测技术专利涉及算法修改和循环预测器增加,性能提升最高可达10%,节约内核功耗最高可达10%。
- 陆家嘴比以赛亚能预测更多分支数目,但总体预测深度差不多,支持长的重复分支语句。
- 重命名宽度和ROB优化:兆芯缩小重命名宽度,从3到2。以及减小ROB大小,从65到48,可能为了节省芯片面积,虽然兆芯一些优化减轻ROB减小带来的乱序重排能力的损失。但这仍然影响了运行向量指令的重排能力,导致运行AVX2性能提升幅度下降。
- 因为设计经验不足或面积考虑,五道口的乱序执行中的寄存器放弃了前代架构中的现代化整数与浮点分离的PRF设计,转为古老的整数与浮点不分离的RRF设计。
- 五道口具有 18 级流水线和 15 个周期的分支预测错误惩罚,相比以赛亚架构的22 级流水线,和20个周期的分支预测错误惩罚,减少了5个周期的错误惩罚,通过减小分支预测错误惩罚,显著改善了性能。
- 评价:IPC提升10~25%,性能提升140%,内存带宽提升120%,分支预测和调度算法优化对提升频率和性能影响显著,但设计能力偏弱,导致竞争力不足。
CNS ,2020年推出
- CNS的前端出自国内兆芯团队设计。
- CNS采用分支预测和指令缓存耦接的取指架构。分支预测单元提供取指请求,然后指令缓存取指,在解码后送入一个24条目的微指令队列,并传给译码单元,最终形成后端的指令供给。
- CNS的TAGE预测器虽然可以识别很长的循环的分支走向,但准确率不如Haswell高,并且循环越长,识别的延迟越高,这限制了它提升频率的上限。在缓存了超过4096条目的指令但小于32KB时,分支指令延迟变成8个周期。
- 对于单个间接分支,CNS可以存 256 个分支,每个分支最多有 4 个目标。大部分情况下可以跟踪大约24个目标,最多可以达到128个。大约有1024个总的间接目标被跟踪。
- 在不到 16 个分支的情况下,CNS 可以维持每周期两个取分支。 解码器类似Intel的设计,解码器有3个简单解码器和1个复杂解码器。对于较长的复杂指令,CNS和Haswell需要6个周期才能执行。
- CNS重命名器可以进行zero-idiom操作,将某个寄存器清零,例如XOR EAX, EAX。重命名器可以分配一个全新的目标寄存器,然后立即将其清零。
- CNS似乎没有移动消除能力。寄存器移动指令的寄存器依赖链将以每个周期执行一个。
- CNS具有一个类似Haswell的联合式(unified)的64条目的大型调度器
- CNS 有两个 AGU 端口,每个AGU端口都能够处理加载或存储,额外有一个数据存储端口。 Haswell 具有三个 AGU,允许它在同一周期内执行两次加载和一次存储。永丰和CNS一样,只有两个加载地址单元(load AGU)。
- CNS 的所有加载完全包含在先前存储中的情况都会以 7 个周期的延迟进行处理。
- CNS 拥有72条目的加载队列 + 46条目的存储队列,与以赛亚和陆家嘴不同,它可以在未知地址的存储之前推测性地执行加载,进行推测性内存消歧。
- CNS CPU有4个整数单元,其中2个具有乘法器、位操作单元。整数单元每个周期最多可以处理2条分支指令,重负载下每个周期只处理1条分支指令。
- CNS有3个FP/AVX单元,两个包括浮点乘累加(MAC)单元;第三个FP/AVX单元处理FP除法和加密(AES)加速。所有这三个单元都可以处理AVX整数指令。
- CNS流水线需要20个阶段完成大部分整数操作,对于命中数据缓存的加载,需要22个阶段。它为缓存访问分配了5个阶段,
- Centaur的CHA处理器(CNS是核心)的缓存与Haswell相当,三缓具有8个2MB的切片,通过2×512bit的环形总线连接,该环形总线实际是由两个四核环组成的双环结构,在访问共享2×4=8MB时,具有比访问16MB更高的带宽,实际8个核心总共约100字节/周期的带宽,比Haswell的约80字节/周期要好一些,但Haswell的2×256bit的环形总线频率更高,也更节能。

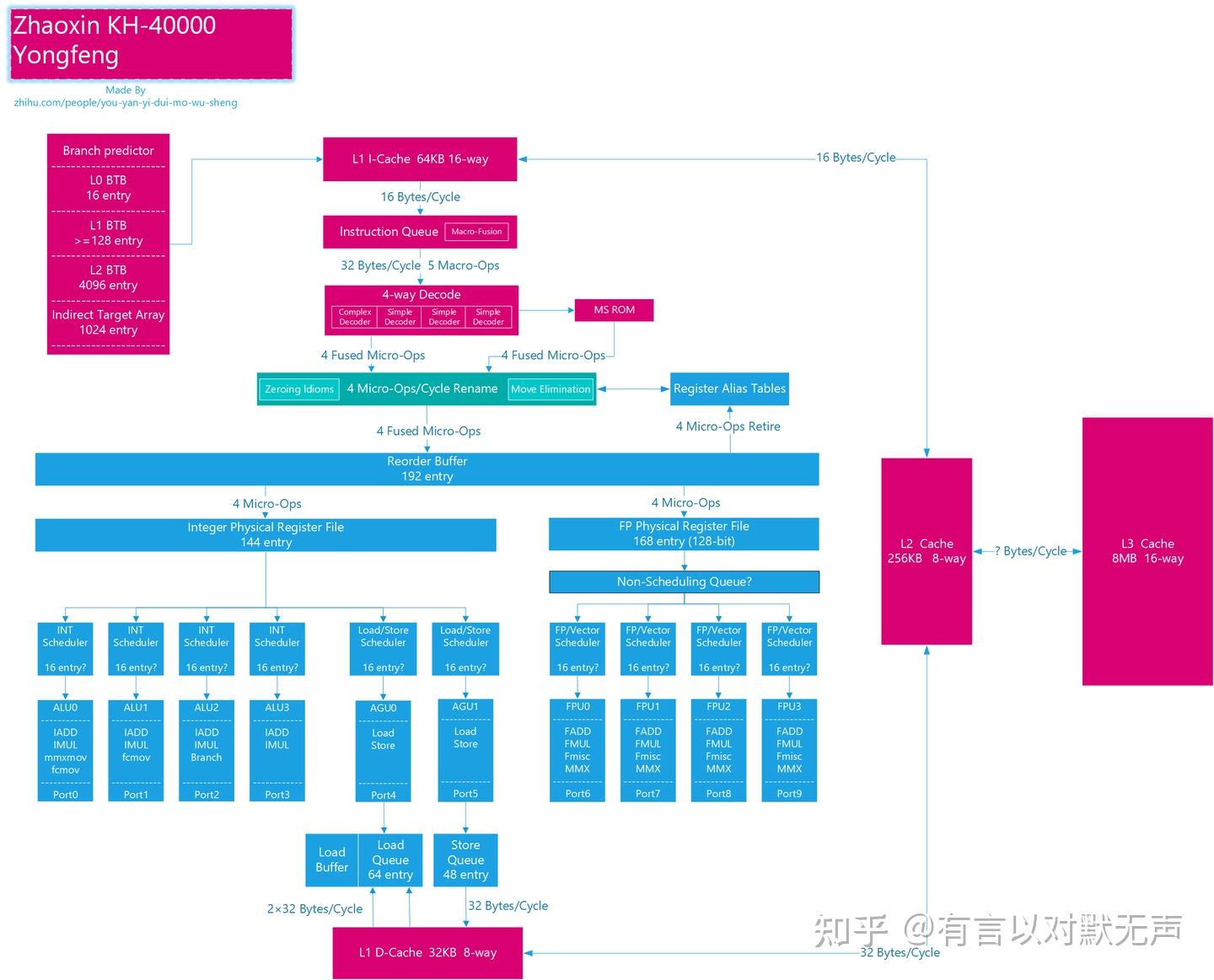
Yongfeng,2022年推出
- 永丰与CNS在前端设计上高度相似,出自兆芯团队设计。
- 永丰采用分支预测和指令缓存耦接的取指架构,分支延迟仍然和CNS一样为3个周期
- 改进了取指延迟,减少一个周期的气泡,提供了较高的频率。
- TAGE预测器性能:永丰采用改进型TAGE预测器,准确率可能接近Haswell水平。
- 永丰和世纪大道能对预取到的16字节指令中最多两条分支指令进行预测,每周期只采取一条。
- CISC解码:永丰的解码器类似Intel设计,具有3个简单解码器和1个复杂解码器。
- 永丰没有设计微指令缓存,可能是出于安全性考虑,避免与幽灵、熔断漏洞相关的攻击。
- 重命名,永丰的重命名器可以进行zero-idiom操作,相比CNS架构还可以进行寄存器移动消除。
- 永丰的调度器可能是类似于Zen的设计,兆芯通过参考Zen的乱序调度,改进并延续了陆家嘴/以赛亚的小型分离式调度器设计,向量寄存器的位宽是128bit与CNS的256bit差别很大,并且每个调度器将微指令发往独属于自己的那个执行端口
- 整数与分支:永丰有4个整数单元,每个单元几乎一样,每个周期只能处理1条分支指令。
- 浮点与向量:永丰有4个128bit位宽的FP/AVX单元,向量整数单元和浮点单元的延迟和吞吐量不如CNS。
- 永丰拥有64条目的加载队列 + 48条目的存储队列,与CNS一样,也可以在未知地址的存储之前推测性地执行加载,进行推测性内存消歧。
- 永丰的所有加载完全包含在先前存储中的情况都会以 6-7 个周期的延迟进行处理,与Zen类似。
- 永丰对乘法做了比较多的优化,部分指令的延迟优于Zen。
- 永丰的地址生成性能大致与Zen类似。
- 永丰的L2的数据预取带宽与Zen类似,为32 Bytes/Cycle,只有CNS的一半。L1数据预取带宽与是Zen的2倍,L1\L2指令预取带宽与是Zen的一半。
- 永丰可能具有18~20级流水线,和Zen1一样有18个周期的分支预测失败惩罚,它为缓存访问分配了4个阶段。
- 采用交叉开关互联,具有较高互联延迟和更低的互联带宽