AMD CPU 微架构的演进
80486,1993年推出
Intel的80486是所有486和586的祖宗。
与其前身一样,80486与所有以前的x86处理器(80386、80286、80186等)保持了完全向后 的目标代码可比性。为了提高性能,英特尔引入了新的片上缓存层(之前存在各种外部扩展)。 8 KB、4 路组关联、回写策略高速缓存对于数据和指令都是一致的。这提供了对最近使用的数据和指令的更快访问。总线接口还进行了各种增强,包括需要单个时钟周期而不是多个时钟周期的更快通信。
而在使用单独封装的数学协处理器(即80387、80287等)之前,80486 将单元移至芯片上,完全消除了外部通信延迟。此外,更先进的数学算法被用来实现新的FPU,从而产生更快的浮点计算。
- Am486是AMD在1990年代生产的80486级计算机处理器家族。
- 英特尔比AMD早将近四年进入市场,但AMD定价其40 MHz的486处理器与英特尔33 MHz的芯片价格相当或低于,提供了约20%更好的性能。
- 尽管竞争对手的486芯片(如Cyrix)的基准性能低于相当的英特尔芯片,AMD的486芯片在按时钟计算的基础上与英特尔的性能相匹配。
- 虽然Am386主要被小型计算机制造商使用,但Am486DX、DX2和SX2芯片在较大的计算机制造商中获得了认可,尤其是宏碁和康柏在1994年时间范围内。
- AMD的高时钟频率的486芯片比许多早期的奔腾芯片提供了优越的整数性能,尤其是60和66 MHz的初次推出产品。而相当的英特尔80486DX4芯片价格高且需要轻微的插座修改,AMD的定价低。英特尔的DX4芯片最初的缓存是AMD芯片的两倍,给了它们稍微的性能优势,但AMD的DX4-100通常比英特尔的DX2-66便宜。 Orko改进的Am486系列支持新功能,如扩展的省电模式和8 KiB的写回L1缓存,后续版本甚至升级到了16 KiB的写回L1缓存。
- 133 MHz的AMD Am5x86是高时钟频率的改进型Am486。

80486是Intel80486系列微处理器的微架构,是80386的后继产品。 89 年 4 月推出的 80486 最初采用1 µm 工艺(后来为800 nm)制造。对于 AMD,这种微架构用于其Am486和Am5x86系列。该架构于 1993 年被 Intel 的P5和1994 年的K5取代。
K5,1996年推出
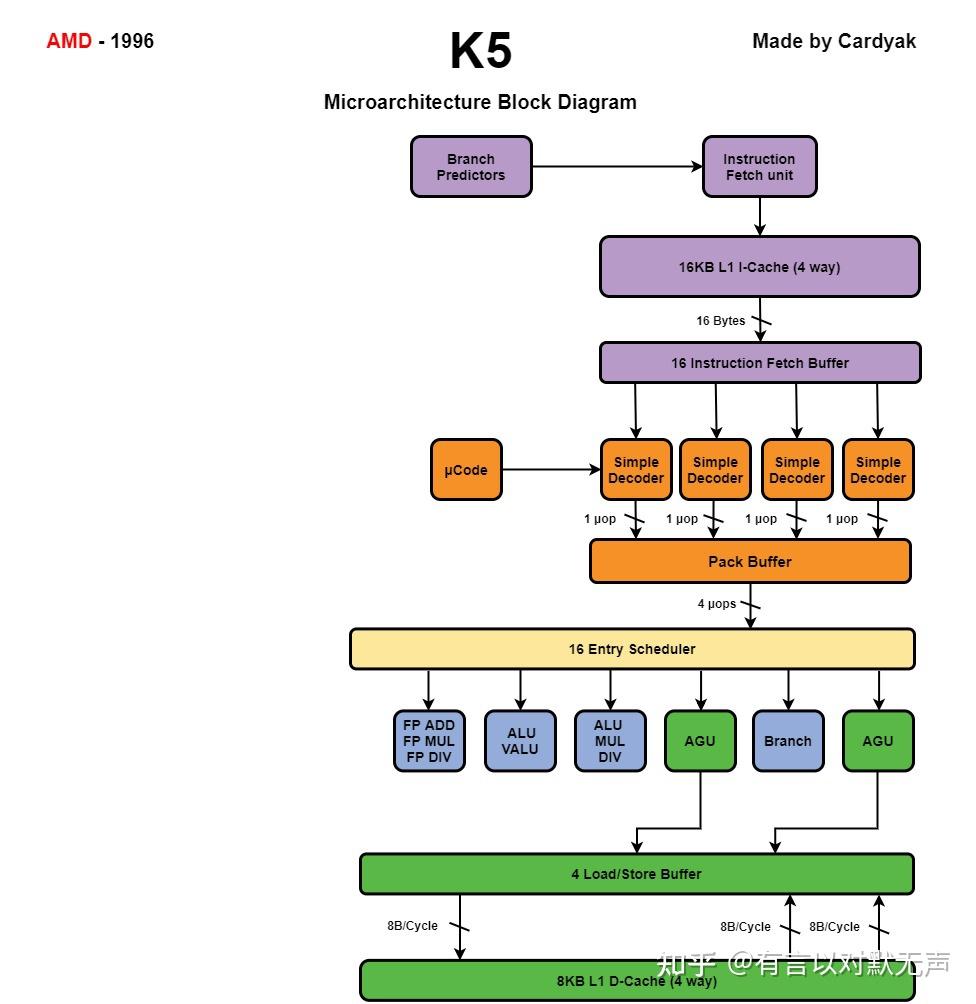
K5 微架构于 1996 年初推出,是 AMD 首款从头开始内部设计的x86微架构,无需获得英特尔架构的许可或进行逆向工程。AMD的K5是第一款完全由公司内部开发的x86处理器。于1996年3月推出,主要竞争对手是英特尔的奔腾微处理器。
- K5是一个雄心勃勃的设计,更接近P6而不是P5。
- 但最终产品在性能上更接近奔腾,尽管IPC与奔腾相比更高。
- K5基于一个内部高度并行的RISC处理器架构,带有一个四宽的x86解码前端。
- K5提供了良好的x86兼容性,公司内部开发的测试套件对后来的项目非常有价值。
- 所有型号都有430万个晶体管,五个整数单元、一个浮点单元可以乱序处理指令。
- 分支目标缓冲区是奔腾的四倍大小,寄存器重命名有助于克服寄存器依赖。
- 芯片对指令的猜测执行减少了流水线停顿。它有16 KB的四路组相联指令缓存和8 KB的数据缓存。
-
浮点除法和平方根微码会经过硬件校验。浮点指令是硬件实现的,并对所有操作数得到真实的数学结果。
- K5项目代表了AMD早期从英特尔夺取技术领导地位的机会。
- 尽管芯片解决了正确的设计概念,但实际的工程实现存在问题。
- 低时钟速率部分是由于AMD当时作为“尖端”制造公司的限制,部分是由于设计本身,在当时的工艺技术中有许多逻辑层级,阻碍了提频。
- 此外,虽然K5的浮点性能被认为优于Cyrix 6x86,但它比奔腾慢,尽管提供更可靠的浮点计算结果。
- 由于上市较晚且未达到性能预期,K5从未像早期的Am486和后来的AMD K6那样获得大型计算机制造商的认可。
K6,1998 年推出
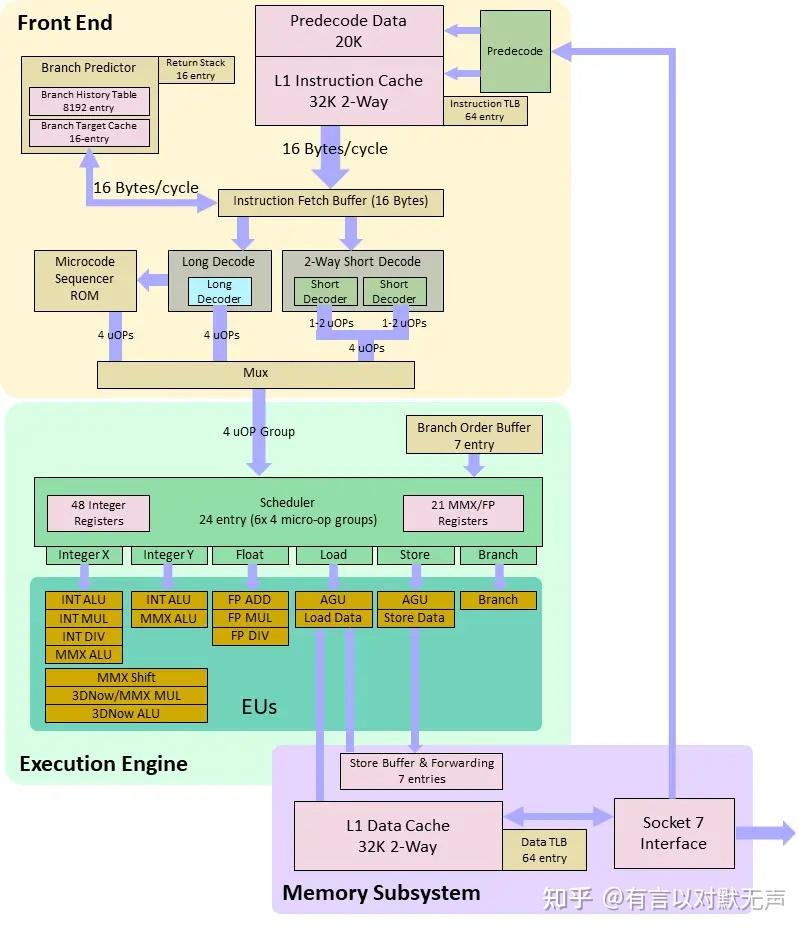
AMD于1998年推出了K6微处理器。这款微处理器的主要优势是它设计成可适配已有的Pentium品牌CPU的桌面设计。它被市场定位为能够与英特尔Pentium II相媲美但价格显著更低的产品。K6对PC市场产生了巨大影响,并给英特尔带来了严峻的竞争。
AMD K6基于NexGen设计的Nx686微处理器,后者在被AMD收购时正在设计。尽管名称暗示其设计是从K5发展而来的,但实际上它是由NexGen团队创建的完全不同的设计,其中包括首席处理器架构师Greg Favor,并在AMD收购后进行了调整。K6处理器包括反馈动态指令重排序机制、MMX指令和浮点单元(FPU)。它还与英特尔的Pentium兼容,可以在广泛使用的“Socket 7”基础的主板上使用。与之前的AMD K5、Nx586和Nx686一样,K6将x86指令即时转换为动态缓冲的微操作序列。
K6最初于1997年4月推出,速度为166和200 MHz。同年晚些时候推出了233 MHz版本。 在 1998 年,AMD 发布了 K6-2,这是一款使用更快总线 (100 MHz) 并改进了 SIMD 性能的处理器。它还比 K6 多了一个 MMX 单元,以及用于浮点计算的新指令集 3DNow!(MMX 仅处理整数)。 K6-2(400 及以上)取得了巨大成功,因为它对于 Pentium MMX 平台的所有者来说是一个很好的升级解决方案 - 通过在具有 66 MHz 总线的主板上使用 2X 倍频器,处理器实际上以 6X 运行( 400 MHz),从而以较低的升级成本显着提高速度。
最后,在1999年,AMD发布了K6的第三个版本,K6-III。与 K6-2 版本的主要区别在于片上 256 KB 缓存。 K6-III 速度非常快,但生产成本也非常高,很快就被 Athlon (K7) 取代。
特点:
- 七个专门用于并行指令的执行单元。
- x86解码器将x86汇编翻译为RISC86指令。
- IEEE 1149.1边界扫描。
- 预测执行优化。
- 乱序执行。
- 寄存器重命名。
K7,1999年推出
jim keller参与开发的知名项目,拥有同时期x86处理器最高的IPC,能耗比吊打netbrust,K7最初采用AMD的180纳米工艺制造。到2002年末,AMD转向130纳米工艺。
架构
K7是AMD的一种相对新的设计,标志着与老化的Socket 7和Super Socket 7的分离。新架构引入了许多重大变化,包括全新的专有Socket A。
与K6 / K6-III的关键变化
- 系统总线
- K7采用DigitalAlpha EV6系统总线接口。
- AMD从Digital公司获得了该技术的许可,使他们能够独立开发自己的芯片组和主板,无需向Intel支付Slot 1 GTL+总线的许可费用。这导致AMD的主板与Intel的主板不兼容。
- EV6采用双数据率(DDR),使总线速度的有效数据传输率翻倍。
- 100 MHz总线= 200 MT/s
- 133 MHz总线= 266 MT/s
- 处理器特性
- K7有三个并行的x86指令译码器,用于将X86指令翻译成定长的微指令,每个微指令可执行1到2个操作。它还有乱序整数管道和乱序多媒体管道。
- K7拥有128KB的L1 Cache,其中64KB用作数据缓存,64KB用作指令缓存。
- 缓存
- L1 Cache的大小对处理器性能至关重要,K7通过L2 Cache的大小和速度以及使用DDR SDRAM作为L2 Cache来提供出色的性能。

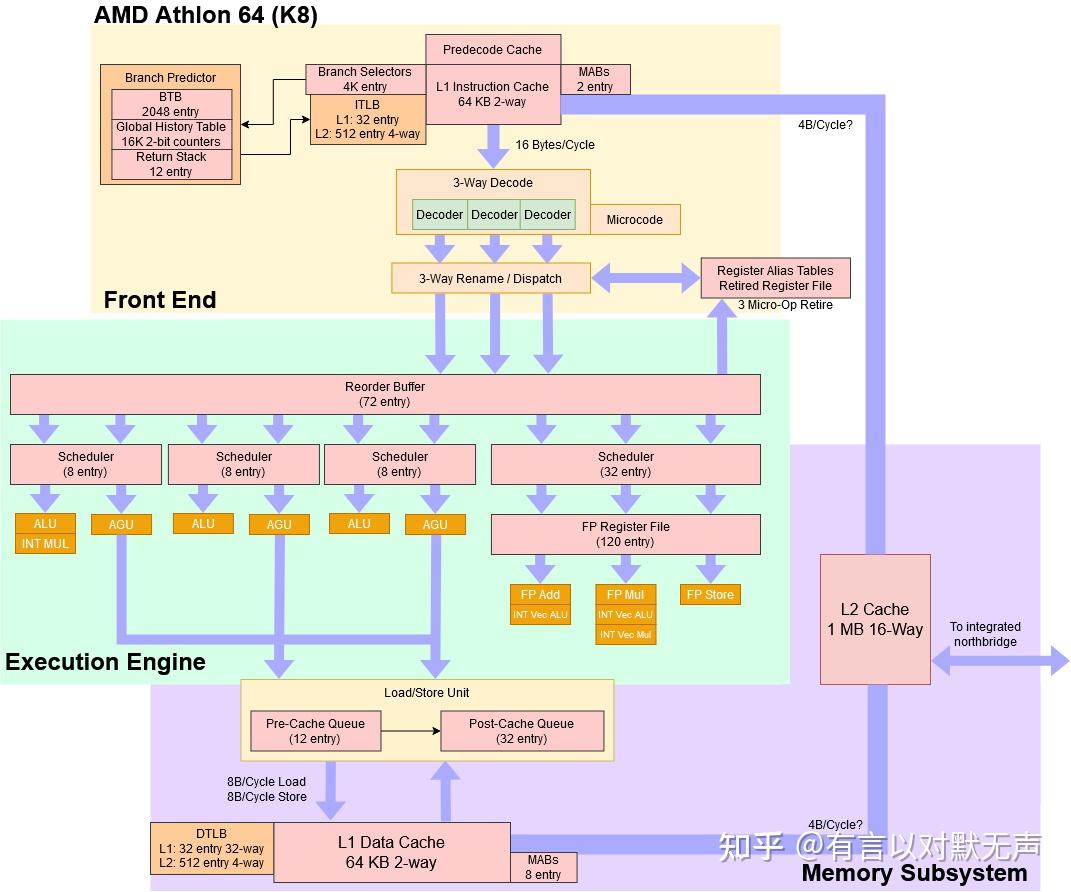
K8,2003 年推出
AMD K8 Hammer也代号为SledgeHammer,作为AMD K7 Athlon微架构的后继产品。 K8 是x86指令集架构的AMD64 64 位扩展的第一个实现
K8 核心与 K7 非常相似。最根本的变化是 AMD64 指令和片上内存控制器的集成。内存控制器极大地减少了内存延迟,并且在很大程度上实现了从 K7 到 K8 的大部分性能提升。
- K8相对于Netburst具有更低的分支错误预测影响,整体表现较为保守。
- AMD没有将分支预测器作为首要任务,K8的分支预测能力明显落后于Netburst。
- K7和K8使用两级预测器,通过全局历史进行预测,但K8的分支预测相对简单。
- K8通过增加历史表大小减少别名几率,具有一定的分支预测准确性。
- K8的分支处理加速,具有单层BTB,BTB实现了最大容量。
- K8的BTB与L1指令缓存相结合,提供分支预测信息,但在缓存和内存子系统方面与Netburst存在显著差异。
- K8的整数执行资源过度复制,具有较低的重新排序容量和基本的微架构特性。
- K8的浮点和矢量执行比Netburst更好,浮点和矢量执行资源过剩。
- K8的内存执行具有存储转发检查,内存访问延迟较低,可以处理大容量缓存。
- K8与Netburst的DRAM访问延迟差异大,K8的新集成内存控制器降低了延迟并提高了带宽。
- K8的整体设计保守,性能表现良好,但分支预测能力明显落后于Netburst。
- K8具有一定的分支预测准确性,但Netburst的预测能力更强,整数执行资源重复。
- K8的分支预测相对简单,可以取消错误路径获取的指令。
- K8的浮点和矢量执行相对Netburst更好,内存执行资源较为简单,但延迟较低。
K10,2007 年推出
K10引入共享三级缓存,同时每个核心拥有自己的一级缓存和二级缓存。如果处理器请求的数据存在于一级缓存中,则直接载入;如果在任何一个二级缓存中,则直接或者通过交叉开关载入一级缓存,并将二级缓存中的原数据标记为无效,这也是AMD的独特设计;如果在三级缓存中,则数据载入后仍然存在,其他核心还能继续访问,从而实现共享。
K10的整合内存控制器(IMC)将有一些新特性,其将可以通过64-bit通道访问内存,使用ECC错误校验的话则是72-bit,这样可以令读取和写入数据同步进行,提高多核CPU在无序访问中的效率。而在CPU的超频性能方面,K10将采用分离式能耗设计IMC也可以根据各个处理器核心独立自定频率和电压,这将令到玩家在超频时可以忽略内存的频率。而在多核心CPU的通信设计方面,K10依然采用内部的交叉开关,全部在处理器之内完成,效率更高。
而在CPU最重要的功耗能耗设计方面,K10采用了一系列的新节能设计,K10架构下,各个处理器可以运行在独立的频率,AMD称之为“P-States”,空闲的核心可以降低频率甚至完全关闭,负载的则全速运行。K10还将配备新的热传感器,以便改善过热保护。
- 指令集的新增和扩展
- 新的位操作指令 ABM:领先零计数 (LZCNT) 和种群计数 (POPCNT)
- 新的 SSE 指令命名为 SSE4a:合并掩码移位指令 (EXTRQ/INSERTQ) 和标量流式存储指令 (MOVNTSD/MOVNTSS)。这些指令在 Intel 的 SSE4 中找不到。
- 支持未对齐的 SSE 加载操作指令(以前需要 16 字节对齐)
- 执行管线增强
- 128 位宽的 SSE 单元
- 更宽的 L1 数据缓存接口,允许每周期进行两次 128 位的加载(而不是 K8 每周期两次 64 位的加载)
- 更低的整数除法延迟
- 512 个间接分支预测器和更大的返回栈(与 K8 相比大小增加了一倍)和分支目标缓冲区
- 侧带栈优化器,专门用于执行寄存器栈指针的增减
- 新技术整合到 CPU 芯片中:
- 四个处理器核心 (四核)
- 为 CPU 核心和内存控制器/北桥分割电源面板,以实现更有效的电源管理,最初由 AMD 称为动态独立核心参与 (Dynamic Independent Core Engagement,D.I.C.E.),现在被称为增强版 PowerNow!(也被称为独立动态核心技术),允许核心和北桥(集成内存控制器)独立地增减功耗。
- 在非负载状态下关闭部分电路,称为“CoolCore”技术。
- 内存子系统的改进:
- 访问延迟的改进:
- 支持将加载重新排序到其他加载和存储操作之前
- 更积极的指令预取,每次预取 32 字节,而不是 K8 的 16 字节
- 用于缓冲读取的 DRAM 预取器
- 缓冲式突发写回到 RAM,以减少争用
- 内存层次结构的变化:
- 直接预取到 L1 缓存,而不是 K8 系列的 L2 缓存
- 32 路组相联的 L3 作为至少 2 MB 的受害者缓存,共享在单个芯片上的处理器核心之间(每个核心具有 512 K 的独立专用 L2 缓存),采用了一种支持共享的替换策略。
- 可扩展的 L3 缓存设计,计划在 45 纳米工艺节点上达到 6 MB,芯片的代号为 Shanghai。
- 访问延迟的改进:
- 地址空间管理的变化:
- 两个 64 位独立的内存控制器,每个都有自己的物理地址空间;这在高度多线程环境中出现随机内存访问时,可以更好地利用可用带宽。这种方法与先前的“交错”设计相反,先前的设计将两个 64 位数据通道限制在单一共享地址空间。
- 更大的标记式查找缓冲区;支持 1 GB 页面条目和一个新的 128 条目的 2 MB 页面 TLB。
- 48 位内存寻址,允许 256 TB 的内存子系统。
- 系统互连的改进:
- HyperTransport 重试支持
- 支持 HyperTransport 3.0,使用 HyperTransport Link unganging 创建每个插槽 8 个点对点链接。
- 平台级别的改进:
- 五个 p 状态,允许自动时钟频率调节
- 增加时钟门控
- 通过 HTX 插槽和空闲的 CPU 插槽,通过 HyperTransport 官方支持协处理器:Torrenza 计划。
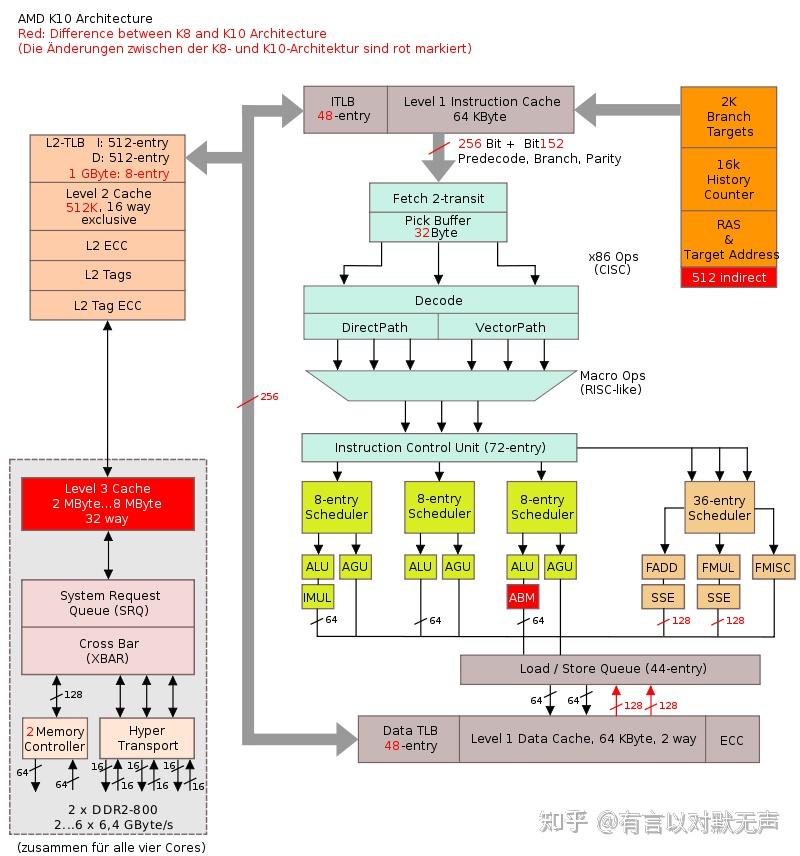
Bulldozer,2011 年推出
大名鼎鼎的推土机架构,Bulldozer Family 15h
- 每个技术爱好者对“AMD FX”或“推土机”这个名字有各种联想。一些人在超频方面有积极体验,但大多数人知道它运行缓慢、热、耗电。也有人知道由于其拉垮的表现,它几乎使AMD破产。
- 在单核性能上,比前身 Greyhound 慢,多核性能仅类似(Phenom II X6 1100T vs FX-8150),却多了两个“核心”。
- 最大负载下的功耗也更高,与英特尔的SandyBridge相比,结果值得怀疑。
- AMD在规划或设计阶段未设想过构建“狗屎产品”。在Bulldozer开发过程中,AMD最初希望它像K10一样,但具有共享的前端和FPU。
- 目标过于雄心勃勃,为了提高32纳米工艺下的频率,因此选择了把架构规模削减,模块化堆积起来。
- Bulldozer采用“集群多线程”(CMT),在处理器的某些部分之间共享两个线程和一些独立部分。
- CMT和SMT都致力于高效利用执行单元,但在竞争执行管线时,会导致一个或多个线程性能下降。
- CMT在整数和浮点代码上运行一对线程时效果最佳,但单线程下整数执行单元闲置较多。
- CMT和典型的SMT处理器在L2缓存的有效共享使用上类似。
- 一个模块由两个“常规”的x86乱序处理核耦合而成,共享早期流水线阶段、FPUs和L2缓存等资源。
- 每个模块拥有独立的硬件资源,包括16 KB的L1d缓存、2 MB的L2缓存、Write Coalescing Cache、两个专用整数核心等。
- Bulldozer的流水线深度为20周期,比K10核心的12周期更长,使得其时钟频率更高,但也增加了延迟和分支错误预测的惩罚。
- Bulldozer整数核心的宽度为四(2 ALU,2 AGU),略小于K10核心的六(3 ALU,3 AGU)。
- 指令集扩展支持Intel的AVX指令集,以及AMD提出的未来128位指令集(XOP、FMA4和F16C)等。
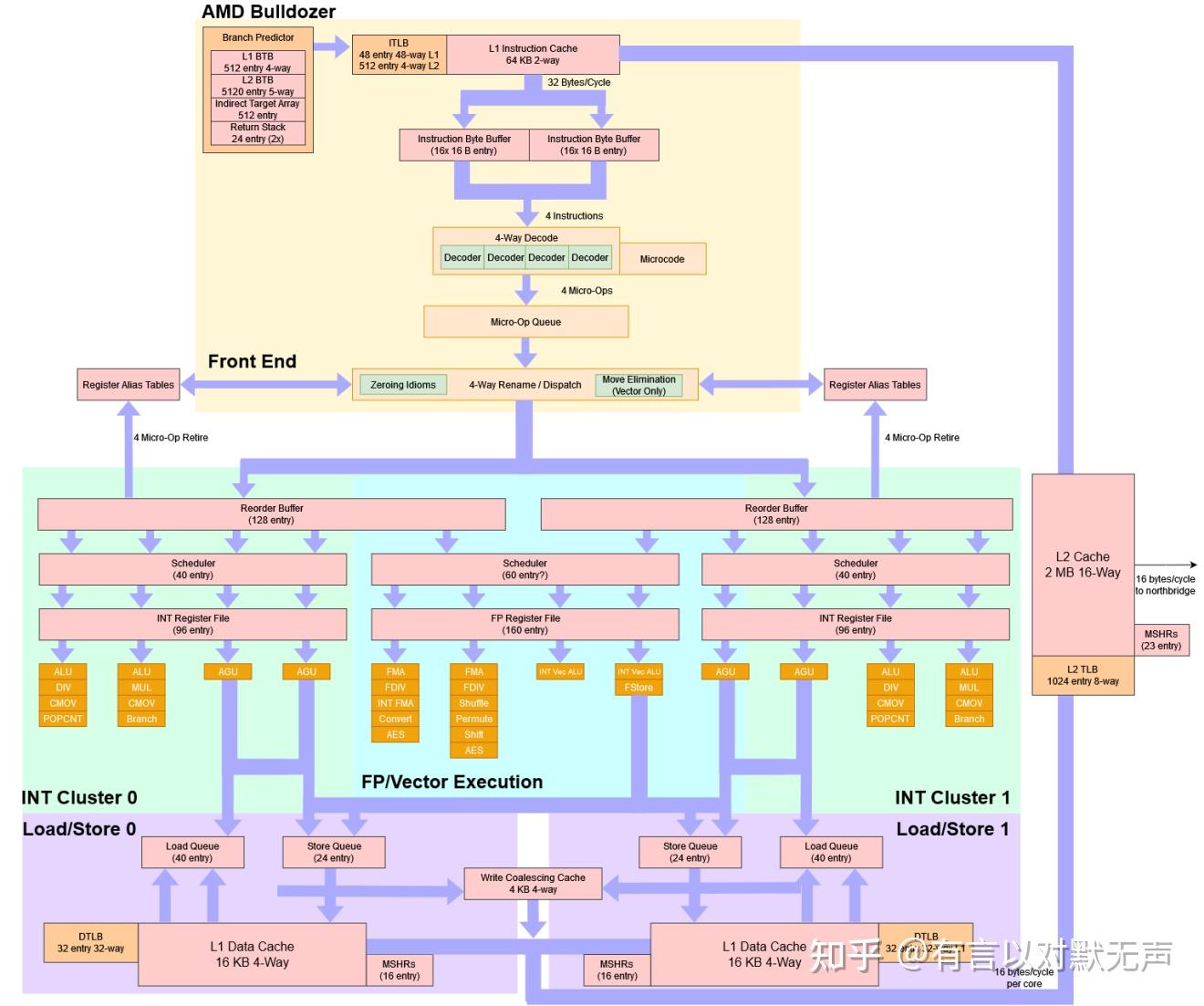
Bobcat,2011 年推出
AMD Bobcat Family 14h 是 AMD 为其 AMD APUs 创建的微架构,面向低功耗/低成本市场。 该核心针对低功耗市场,如上网本/台式机、超轻薄笔记本电脑、消费电子和嵌入式市场。
架构具体特点:
- 64 位核心
- 乱序执行
- 高级分支预测器
- 双 x86 指令解码器
- 带两个 ALU 的 64 位整数单元
- 带两个 64 位管道的浮点单元
- 单通道 64 位内存控制器
- 32 KiB 指令 + 32 KiB 数据 L1 缓存
- 512 KiB - 1 MiB L2 缓存
- MMX, SSE, SSE2, SSE3, SSSE3, SSE4A, ABM
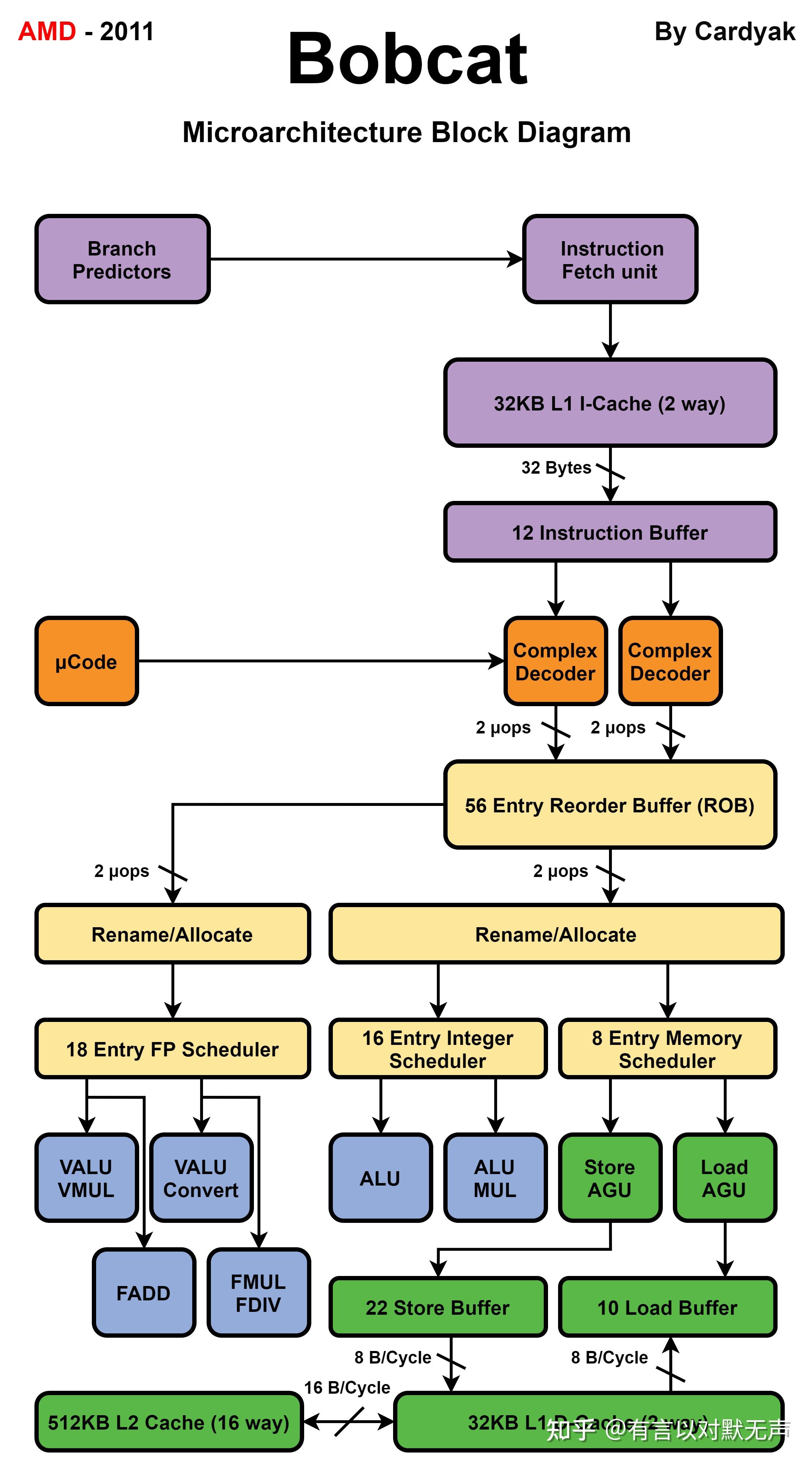
Piledriver,2012 年推出
AMD Piledriver Family 15h 是由 AMD 开发的微架构,作为 Bulldozer 的第二代继任者。 用于 AMD 加速处理单元(前身为 Fusion)、AMD FX 和 Opteron 系列处理器。 与 Bulldozer 相比,Piledriver 的变化是渐进的。 Piledriver 使用相同的“模块化”设计。 它的主要改进是分支预测和 FPU/整数调度,以及转换为硬边缘触发器以改善功耗。 这导致时钟速度提高了 8-10%,性能增加了约 15%,功耗特性相似。
设计:
- Piledriver 在原始 Bulldozer 微架构上有所改进:
- 集群化多线程
- 更高的时钟速率
- 每时钟周期的指令 (IPC) 改进
- 更低的功耗和温度
- Turbo Core 3.0
- 更快的集成内存控制器 (IMC)
- 固定硬件除法器
- 改进的分支预测和预取
- 感知器分支预测器
- 改进的浮点和整数调度
- 支持高级向量扩展 (AVX) 1.1、FMA3、BMI1 和 TBM
- 更大的 L1 翻译后看缓冲区 (TLB) 和 L2 效率改进
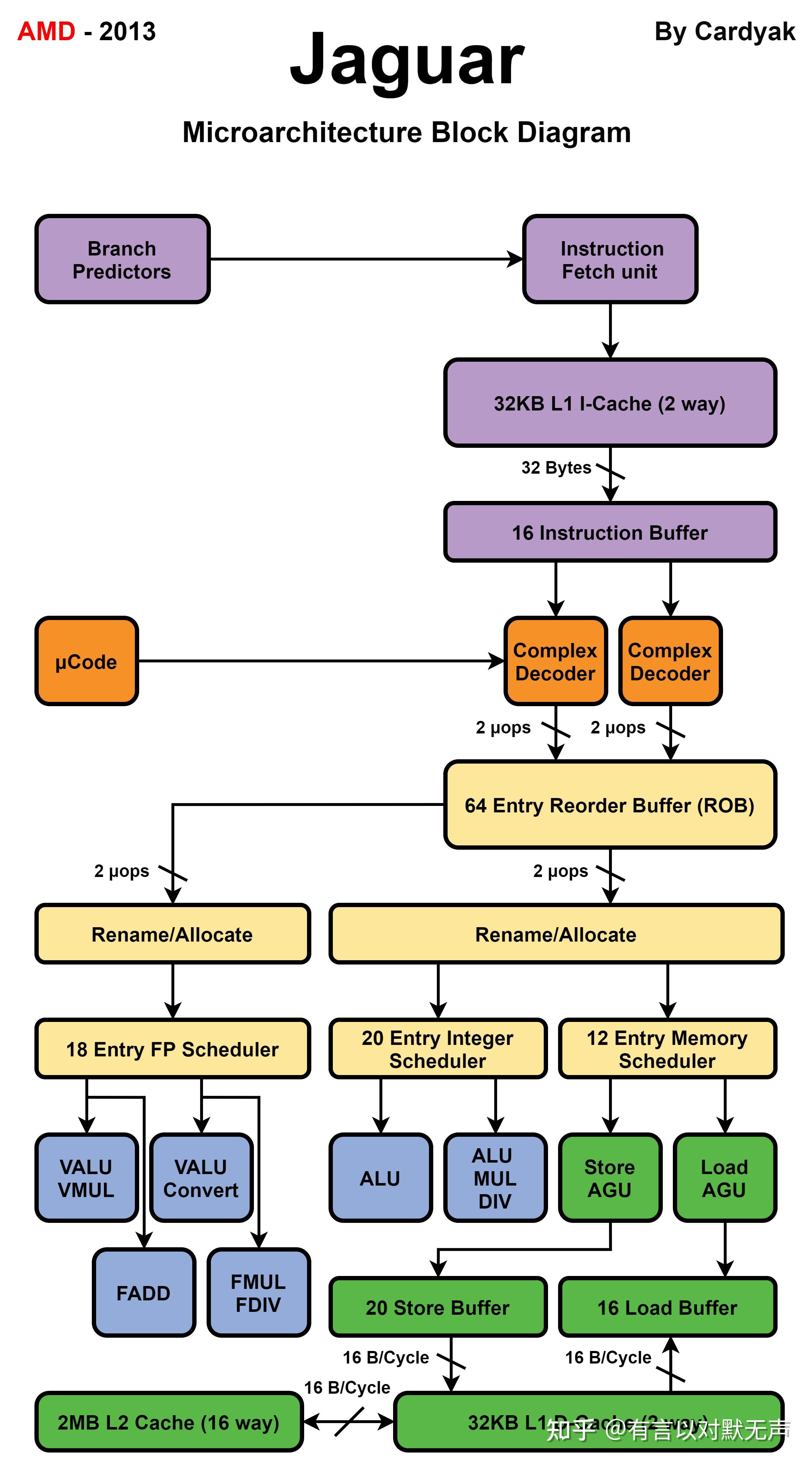
Jaguar,2013年推出
- AMD Jaguar Family 16h 是由 AMD 设计的低功耗微架构,用于 2013 年继承 Bobcat Family 微架构之后的 APU,并在 2014 年被 AMD 的 Puma 架构继承。
- 它是两路超标量,能够进行乱序执行。
- 它被用于 AMD 的半定制业务部门作为定制处理器的设计,并被 AMD 用于四个产品系列:Kabini 针对笔记本电脑和迷你电脑、Temash 针对平板电脑、Kyoto 针对微型服务器,以及面向嵌入式应用的 G 系列。
- PlayStation 4 和 Xbox One 使用基于 Jaguar 微架构的芯片,比 AMD 在其自己的 Jaguar APU 中销售的 GPU 更强大。
- Jaguar 处理器的结构:每个核心有 32 KiB 指令 + 32 KiB 数据 L1 缓存,L1 缓存包含奇偶校验错误检测;16路、1–2 MiB 的 L2 缓存,由两个或四个核心共享,L2 缓存通过使用纠错码来保护免受错误影响;乱序执行和推测执行;集成内存控制器;两路整数执行;两路 128 位宽的浮点和打包整数执行;整数硬件除法器;消费级处理器支持一通道内最高频率为 1600 MHz 的两个 DDR3L DIMM;服务器处理器支持带 ECC 的一通道内最高频率为 1600 MHz 的两个 DDR3 DIMM;作为 SoC(不仅是 APU),它集成了 Fusion 控制器中枢;
- Jaguar 不支持模块化多线程(CMT),意味着执行资源不共享。
- Jaguar 核心支持以下指令集和指令:MMX、SSE、SSE2、SSE3、SSSE3、SSE4a、SSE4.1、SSE4.2、AVX、F16C、CLMUL、AES、BMI1、MOVBE(大端序移动指令)、XSAVE/XSAVEOPT、ABM(POPCNT/LZCNT)和 AMD-V。
- 与 Bobcat 相比的改进:时钟频率增加超过 10%;每时钟周期指令数(IPC)提高超过 15%;添加对 SSE4.1、SSE4.2、AES、CLMUL、MOVBE、AVX、F16C、BMI1 的支持;最多四个 CPU 核心;L2 缓存在核心之间共享;FPU 数据路径宽度增加至 128 位;添加硬件整数除法器;增强的缓存预取器;负载-存储单元带宽加倍;C6 和 CC6 低功耗状态,具有更低的进入和退出延迟;每个核心更小,面积为 3.1 mm2。
- Jaguar 是一个 64 位、乱序微处理器,每个周期解码和发出 2 条指令,并分派 6 个操作。四个 Jaguar 核心组成一个集群,共享一个 L2 缓存。
Puma Family 16h于2014年发布
- Puma核心采用与Jaguar相同的微架构,并继承了以下设计:
- 乱序执行和投机执行,最多4个CPU核心
- 双路整数执行
- 双路128位宽浮点和打包整数执行
- 整数硬件除法器
- Puma不支持集群多线程(CMT),即没有“模块”
- Puma不支持异构系统架构或零拷贝
- 每个核心32 KiB指令+32 KiB数据L1缓存
- 由两个或四个核心共享的1-2 MiBL2缓存
- 集成单通道内存控制器,支持64位DDR3L
- 每个核心占据3.1 mm2的面积
- 指令集支持
- 类似Jaguar,Puma核心支持以下指令集和指令:MMX、SSE、SSE2、SSE3、SSSE3、SSE4a、SSE4.1、SSE4.2、AVX、F16C、CLMUL、AES、BMI1、MOVBE(大端指令移动)、XSAVE/XSAVEOPT、ABM(POPCNT/LZCNT)和AMD-V。
改进
- 在1.2V时,CPU核心泄漏减少了19%
- GPU泄漏减少38%
- 内存控制器功耗减少500 mW
- 显示接口功耗减少200 mW
- 根据机箱温度智能提升增压
- 根据应用程序需求选择性增压(智能增压)
- 通过集成的Cortex-A5处理器支持ARM TrustZone
- 支持DDR3L-1866内存
Steamroller,2014年推出
- 作为 Bulldozer 的第三代继任者。Steamroller的重点是实现更大规模的并行性。
- 改进的核心在于模块内每个核心都有独立的指令解码器,每个线程的最大宽度分派量增加了25%,指令调度器更好,改进的感知分支预测器,更大更智能的高速缓存,最多减少30%的指令缓存缺失,分支错误率减少20%,动态可调整大小的L2高速缓存,微操作队列,更多内部寄存器资源和改进的内存控制器。
- AMD估计这些改进将使每个周期的指令(IPC)比第一代Bulldozer核心提高30%,同时保持Piledriver的高时钟速率并降低功耗。
- 最终结果是与Piledriver相比,单线程IPC提高了9%,多线程IPC提高了18%。
Excavator,2015年推出
- 作为 Bulldozer 的第四代继任者
- Excavator 添加了对AVX2、BMI2和RDRAND等新指令的硬件支持。Excavator 采用通常用于GPU 的高密度库进行设计,以减少电能消耗和芯片尺寸,从而将能源使用效率提高 30% 。与 AMD 之前的核心 Steamroller 相比,Excavator 可以多处理多达 15% 的指令。
- AMD Puma Family 16h是AMD为其APU推出的低功耗微架构。它是第二代版本,继承了Jaguar的地位,面向相同市场,并属于同一AMD架构Family 16h。
- Beema系列处理器面向低功耗笔记本电脑,而Mullins则面向平板电脑领域。
Zen,2017年推出
- Zen(family 17h)是一种全新的设计,AMD继续保持他们的过去的传统设计理念,这体现在诸如分离式调度器、分离式FP和int&memory执行单元等设计选择中。从宏观角度看,Zen与其前身共享许多相似之处,但引入了新元素和重大变化。
- 每个核心由一个前端(顺序区域)组成,负责获取指令、解码、生成µOP和融合µOP,并将它们发送到执行引擎(乱序部分)。
- 指令可以从L1I$获取,也可以来自µOP缓存(后续获取),完全消除了解码阶段。
- Zen将4条指令/周期解码为µOP队列。µOP队列将单独的µOP分派到整数端和FP端(在可能的情况下同时分派到两者)。
- Zen最大的变化是回归传统核心分区设计 - 每个核心都是独立核心,拥有自己的浮点/SIMD单元和L2缓存,之前这些单元是两个核心共享的。
- 与英特尔的许多最近微架构(如Skylake和Kaby Lake)使用联合式调度器不同,AMD继续使用分离式调度器设计。
- µOP在µOP队列处解耦,并通过两个不同的管线发送到整数端或FP端。这两个部分完全独立,每个部分都有单独的调度器、队列和执行单元。
- Zen支持所有现代x86扩展,包括AVX/AVX2、BMI1/BMI2和AES。Zen还支持SHA,这是一种安全哈希实现指令,目前仅在英特尔的超低功耗微架构(例如Goldmont)中找到,但在他们的主流处理器中没有。
- 从内存子系统的角度看,数据通过L1D$进入执行单元,通过加载和存储队列(两者的容量几乎翻了一番)和两个地址生成单元(AGUs)以每周期2次加载和1次存储的速率。
- 每个核心还有一个512 KiB的L2缓存。L2以每周期32B的速率将数据馈送到一级数据和一级指令缓存(每个周期32B可以在两个方向(双向总线)中发送)。
- L2连接到L3缓存,后者跨所有核心共享。与L1到L2的传输一样,L2每个周期也以32B的速率将数据传输到L3,反之亦然。
- 前端:Zen核心的前端处理顺序操作,如指令获取和解码。指令获取由两个路径组成:传统的解码路径,指令来自指令缓存,以及µOP缓存,由分支预测(BP)单元确定。
- 分支预测单元解耦,可以在接收到所需操作(如重定向)后立即开始工作,超前于传统的指令获取。
- Zen将指令TLB移动到BP(比在以前的架构中早得多的阶段)。这样做是为了通过允许更积极的预取,使物理地址在更早的阶段检索到。
- 解码是x86的最大弱点,解码器是整个微架构中最昂贵和最复杂的方面之一。指令的长度可从一个字节到十五个字节不等,确定指令边界本身就是一个复杂的任务。
- 解码是通过4个Zen解码器完成的。解码阶段允许每个周期解码四个x86指令,这些指令随后发送到µOP队列。
- 由于需要执行x86,有些指令实际上包含多个操作。其中一些操作在OoOE设计中无法有效实现,因此必须转换为更简单的操作。
- 在Zen,复杂的x86指令被分解为更简单的固定长度操作,称为宏操作或MOPs。这些MOPs可以进一步分解为更简单的固定长度操作,称为微操作(µOPs)。
- µOPs缓存不是一个跟踪缓存,而更像是英特尔在Sandy Bridge微架构中使用的缓存。µOPs缓存是一个独立的单元,不是L1I$的一部分,也不一定是L1I缓存的子集。当一个存储在µOPs缓存中的指令被从L1中驱逐时,就会发生这种情况。在获取阶段,必须从两个路径进行探测。
- 解码阶段允许每个周期解码四个x86指令,这些指令随后发送到µOP队列。以前,在Bulldozer/Jaguar设计中,AMD有两条路径:FastPath Single生成单个MOP,FastPath Double生成两个MOP,然后发送到调度器。Zen有着更加密集的MOPs,几乎所有指令都是FastPath Single。
- Dispatch能够将6个µOP发送到整数EX,最多4个µOP发送到浮点FP EX。 Zen可以同时向两者分派(即每周期最多10个µOP),但由于退休控制单元(RCU)最多只能处理6个MOPs/周期,实际发送的µOPs数量可能较低。
-
第三条路径可能会抵达的是微代码序列器(MS)ROM。发出超过两个MOP的指令将被重定向到微码ROM。
- 优化:在这个阶段利用了许多优化机会,如堆栈引擎、µOP融合等。
- 堆栈引擎:在解码阶段,Zen将堆栈引擎Memfile(SEM)整合到设计中。SEM坐落在队列和调度之间,监控MOP流量。SEM可以立即进行存储到加载的转发,以匹配后续指令的堆栈指针,实现零延迟指令。 µOP-Fusion:在这个阶段,Zen执行额外的优化,如微操作融合或分支融合 - 将比较和分支操作组合成单一µOP。
- 执行引擎:Zen的执行引擎(后端)分为两个主要部分:整数和内存操作以及浮点操作。整数和FP部分都可以访问192个条目的退休队列,并且每个周期可以退休8个指令。
- 整数执行可以每周期接收最多6个µOPs,Zen具有168个条目的物理64位整数寄存器文件。
- 浮点侧可以每周期接收最多4个µOPs,Zen具有160个条目的物理128位浮点寄存器文件。
- 存取指令是从两个AGUs进行的,它们可以同时操作。 Zen具有44个条目的加载队列和44个条目的存储队列。
- 内存子系统:Zen的内存子系统允许每周期进行两次加载(每次16B)和一次存储(16B)。 Zen的L1 TLB是64条目,L2 TLB是1536条目,不支持1 GiB页面。Zen包含64 KiB 4路组相联的L1指令缓存和32 KiB 8路组相联的L1数据缓存。
- 浮点指令有较高的延迟,可能会在Dispatch处积压。非调度队列(NSQ)试图减少这种情况,通过排队更多的FP指令,使Dispatch在整数侧继续进行。除此之外,NSQ还可以提前开始处理FP指令的内存组件,以便它们在通过调度队列后准备就绪。 FP调度程序具有四个管道(比Excavator多一个),其上的执行单元可操作128位浮点。
- FP可以执行所有矢量操作。简单的整数矢量操作(如移位、加法)都可以在一个周期内完成,这是AMD以前架构的一半延迟。基本浮点数学的延迟为三个周期,包括乘法(双精度多一个周期)。浮点数具有一个单独的管道用于128位加载操作。
- Zen还支持SHA和AES,其中AES单元位于浮点调度程序的管道0和1上。Loads和Stores通过两个AGUs进行,Zen具有44个条目的加载队列和44个条目的存储队列。
- 内存子系统允许每周期进行两次加载(每次16B)和一次存储(16B)。 Zen的L1 TLB是64条目,L2 TLB是1536条目,不支持1 GiB页面。Zen包含64 KiB 4路组相联的L1指令缓存和32 KiB 8路组相联的L1数据缓存。 L2缓存是512 KiB 8路组相联的缓存,包含在核心内,不与其他核心共享。 L2缓存每个周期可以读取和写入32B/cycle到8MB L3缓存(每个周期32B双向总线)

Zen+于2018年推出是,Zen的小幅度修改,改了预取并让桌面Zen+,基于 Zen 的 APU上的对于所有访问模式都有 12 个周期的 L2 延迟,原来是17个周期的 L2 延迟。
Zen2,2019年推出
- 前端
- 前端吞吐量得到了提高,以满足支持 256 位操作的后端需求。
- AMD 对分支预测单元进行了改进,包括对预取器和指令缓存的优化。
- 分支预测单元的作用是指导指令获取,避免流水线停滞或执行错误路径。
- Zen 2 的分支预测单元容量翻倍,引入了 TAGE 预测器,并减少了误预测率。
- 指令获取和解码单元每周期读取 32 字节,支持 20 个字节宽度的指令字节队列。
- 整数执行单元
- 包括专用重命名单元、五个调度器、180 个条目的物理寄存器文件、四个 ALU 和三个 AGU 管道,以及 224 个条目的退休队列。
- ALU 调度器队列深度增加到 16 个条目,支持移动消除,减少资源占用。
- 浮点单元
- 包括专用重命名单元、一个 4 发射的乱序调度器、160 条目的物理寄存器文件和四个执行管道。
- 物理寄存器、执行单元和数据路径的宽度扩展至 256 位。
- 支持超前执行和存储器数据预测优化。
- 载入-存储单元
- 处理内存读取和写入,数据路径和缓冲区宽度从 128 位提高到 256 位。
- 支持内存类型范围寄存器(MTRR)和页面属性表(PAT)扩展。
- 每个核心有 512 KiB 的 L2 缓存,支持 ECC 保护。
- 多预测模式和优化
- 支持分支融合,将 CMP 或 TEST 指令与条件分支组合成一个宏操作。
- 采用硬件页表漫步等高级缓存技术优化性能。
- 操作缓存(OC)
- 512 条目、8 路组相联、奇偶校验保护的缓存,提高指令解码和吞吐量。
- 可每周期发送 8 个宏操作到微操作队列,取代传统的指令获取和解码流水线。
- 微操作队列和重定向
- 未公开深度的微操作队列,支持指令解码和调度的分离。
- 支持分支结果重定向指令获取和精炼预测。
- 栈引擎和内存依赖预测
- 栈引擎优化指令依赖,支持内存依赖预测,提高执行效率。
- 支持对存储器的非瞬时写入优化,减少总线利用率。
- 页表技术和TLB
- 支持硬件页表漫步和页表项(PTE)合并,提高内存地址转换效率。
- 有 64 条目的 L1 数据 TLB 和 2048 条目的 L2 数据 TLB,支持快速地址转换。
- 性能提升和效率优化
- 提高指令分派带宽和退休带宽,优化执行引擎和数据路径。
- 支持浮点运算器的异步执行,提高执行效率和时钟频率。
- CCX
- 2倍大的L3缓存切片(从8 MiB增加到16 MiB)
- 增加的L3延迟(约40个周期,从约35个周期增加)
- 安全性
- 增强的Spectre技术
- 支持的密钥/虚拟机数量增加
- I/O
- PCIe 4.0(从3.0)
- Infinity Fabric 2
- 每个链路的传输速率增加2.3倍(从约10.6 GT/s增加到25 GT/s)
- MemClk与FClk解耦,支持2:1比例以及1:1比例
- 支持DDR4-3200,从DDR4-2933增加
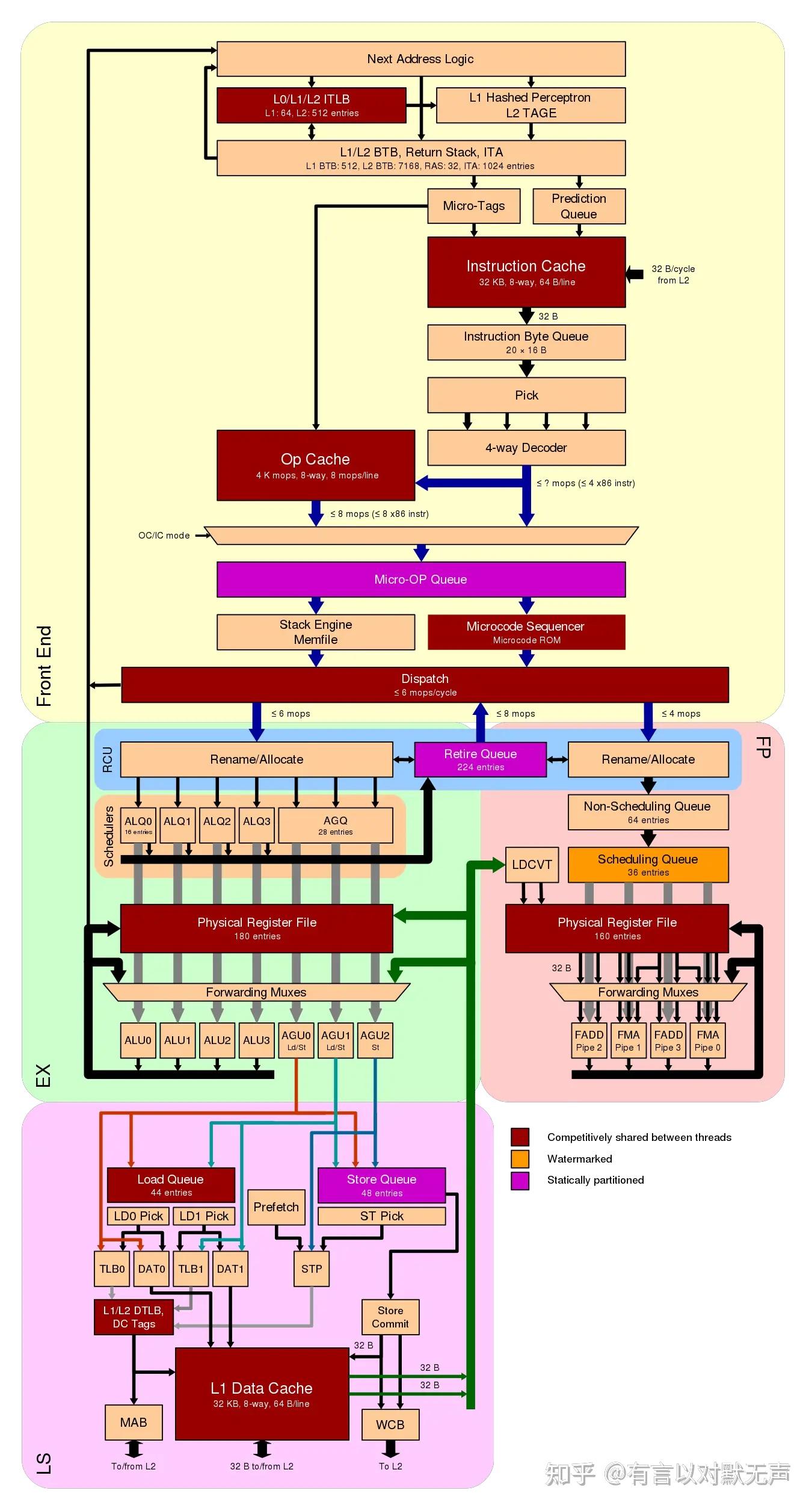
Zen3,2020年推出
- CCD
- 统一的8核心CCX(每个CCD来自2个4核心CCX)
- 32 MiB L3$均等分配给CCD中的所有核心。
- L3延迟增加(约46个周期,从约40个周期增加)
- 前端
- 增加的分支预测带宽 “零气泡”分支预测
- L1 BTB从512个条目增加到1024个条目
- 改进的预取
- 改进的µop缓存
- 后端
- 浮点数单元:
- FMA延迟从5个周期减少到4个周期。
- 添加第五和第六个专用执行端口用于浮点存储和FP-to-int传输,不再共享第二个FADD端口。
- 将调度器分成每个FMA/FADD/传输端口组一个调度器。
- 256b VAES和VPCLMULDQ支持加倍AES和AES-GCM的加密吞吐量。
- 与之前的微码模拟相比,BMI2 PDEP/PEXT位分散/收集操作的硬件实现。
- 整数单元:
- 整数物理寄存器文件从180增加到192个条目
- 发射宽度增加从7(现有的4个ALU和3个AGU)到10,其中包括1个新的专用分支执行端口和2个分离的存储数据路径。
- 调度器在ALU + AGU/分支端口对之间共享,而不是每个端口专用。
- 在更广泛的指令流上增加端口之间的指令冗余以减少瓶颈。
- 8/16/32/64位有符号整数除法/取模延迟从17/22/30/46个周期减少到10/12/14/20个周期。(对于一些旧/新情况的一些无符号操作速度快约1个周期。)吞吐量成比例提高。
- 浮点数单元:
- 加载/存储:
- 如果不是256b,则加载吞吐量从2增加到3。
- 如果不是256b,则存储吞吐量从1增加到2。
- 存储队列从48增加到64个条目。
- 页表步进器从2增加到6,用于TLB缺失处理。

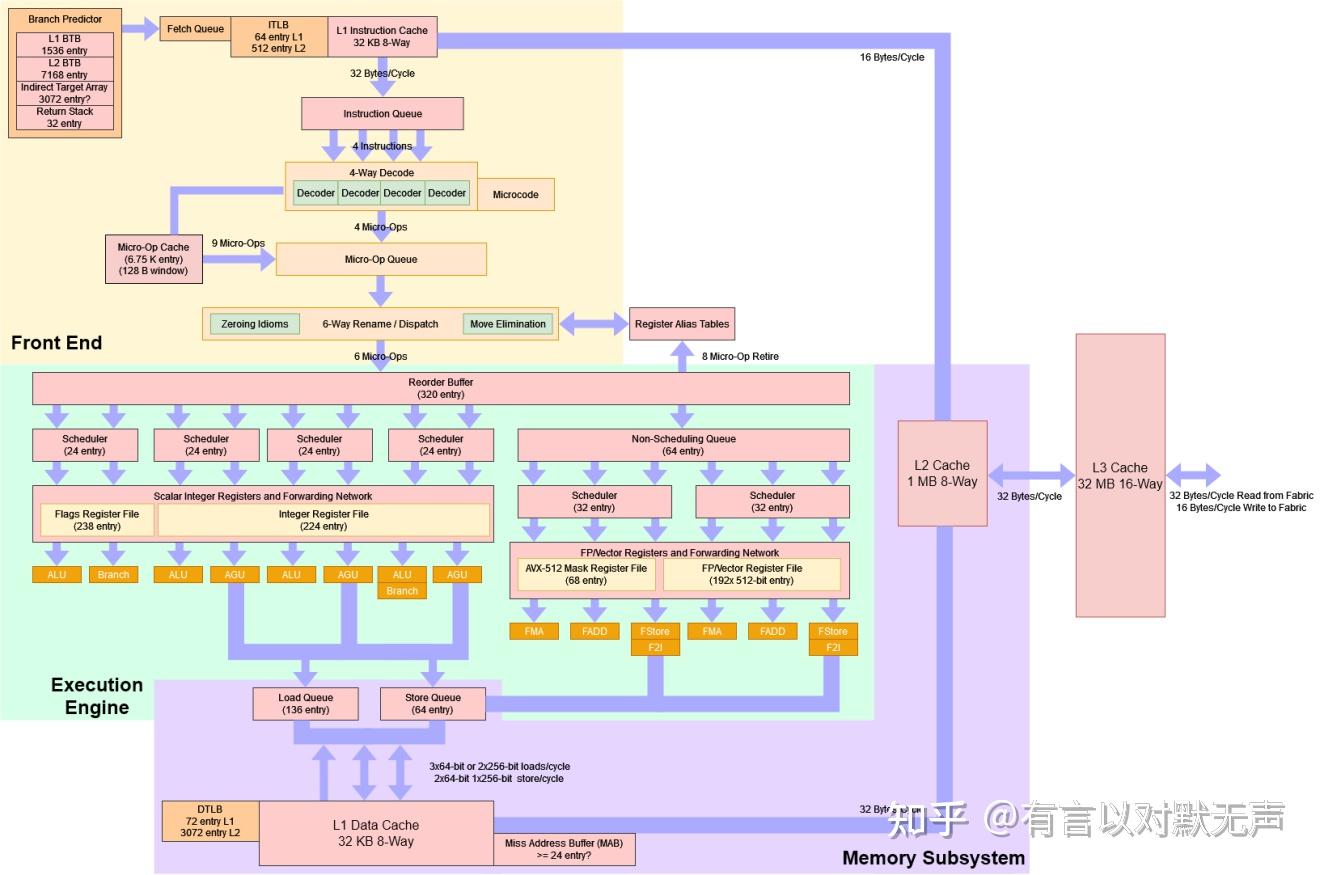
Zen4,2022年推出
- Zen 4看起来与Zen 3相似,但在整个流水线中有各种升级
- Zen 4的分支目标追踪能力比Golden Cove更好
- Zen 4比Golden Cove在处理间接分支时表现更好
- Zen 4在分支跟踪方面比Zen 3明显更优秀
- Zen 4的分支重命名能力提升,具有更大的优势
- Zen 4增加了微操作缓存的大小,4k->6.75k
- Zen 4的重命名器能够更好地管理后端资源,拥有更高的重命名IPC
- Zen 4的ROB容量有所增加
- Zen 4的调度器和执行管道布局与Zen 3相同
- Zen 4引入了AVX-512指令集扩展,可在合适的应用中获得明显的性能优势
- Zen 4的AVX-512实现在性能和面积之间取得了平衡
- Zen 4的前端和执行引擎改进显著
- Zen 4的后端重命名能力提升,更好地吸收缓存和执行延迟
- Zen 4在整数方面表现强劲
- Zen 4在加载和存储带宽方面略显落后